kwcoco.coco_dataset module¶
An implementation and extension of the original MS-COCO API [CocoFormat].
Extends the format to also include line annotations.
The following describes psuedo-code for the high level spec (some of which may
not be have full support in the Python API). A formal json-schema is defined in
kwcoco.coco_schema.
Note
The main object in this file is CocoDataset, which is composed of
several mixin classes. See the class and method documentation for more
details.
An informal description of the spec given in: coco_schema_informal.rst.
For a formal description of the spec see the coco_schema.json, which is generated by :py:mod`kwcoco/coco_schema`.
Todo
- [ ] Use ijson (modified to support NaN) to lazilly load pieces of the
dataset in the background or on demand. This will give us faster access to categories / images, whereas we will always have to wait for annotations etc…
[X] Should img_root be changed to bundle_dpath?
[ ] Read video data, return numpy arrays (requires API for images)
[ ] Spec for video URI, and convert to frames @ framerate function.
[x] Document channel spec
[x] Document sensor-channel spec
[X] Add remove videos method
- [ ] Efficiency: Make video annotations more efficient by only tracking
keyframes, provide an API to obtain a dense or interpolated annotation on an intermediate frame.
- [ ] Efficiency: Allow each section of the kwcoco file to be written as a
separate json file. Perhaps allow genric pointer support? Might get messy.
[ ] Reroot needs to be redesigned very carefully.
[ ] Allow parts of the kwcoco file to be references to other json files.
[X] Add top-level track table
[ ] Fully transition to integer track ids (in progress)
References
- class kwcoco.coco_dataset.MixinCocoDepricate[source]¶
Bases:
objectThese functions are marked for deprication and will be removed
- keypoint_annotation_frequency()[source]¶
DEPRECATED
Example
>>> import kwcoco >>> import ubelt as ub >>> self = kwcoco.CocoDataset.demo('shapes', rng=0) >>> hist = self.keypoint_annotation_frequency() >>> hist = ub.odict(sorted(hist.items())) >>> # FIXME: for whatever reason demodata generation is not determenistic when seeded >>> print(ub.urepr(hist)) # xdoc: +IGNORE_WANT { 'bot_tip': 6, 'left_eye': 14, 'mid_tip': 6, 'right_eye': 14, 'top_tip': 6, }
- class kwcoco.coco_dataset.MixinCocoAccessors[source]¶
Bases:
objectTODO: better name
- delayed_load(gid, channels=None, space='image')[source]¶
Experimental method
- Parameters:
gid (int) – image id to load
channels (kwcoco.FusedChannelSpec) – specific channels to load. if unspecified, all channels are loaded.
space (str) – can either be “image” for loading in image space, or “video” for loading in video space.
Todo
- [X] Currently can only take all or none of the channels from each
base-image / auxiliary dict. For instance if the main image is r|g|b you can’t just select g|b at the moment.
- [X] The order of the channels in the delayed load should
match the requested channel order.
[X] TODO: add nans to bands that don’t exist or throw an error
Example
>>> import kwcoco >>> gid = 1 >>> # >>> self = kwcoco.CocoDataset.demo('vidshapes8-multispectral') >>> delayed = self.delayed_load(gid) >>> print('delayed = {!r}'.format(delayed)) >>> print('delayed.finalize() = {!r}'.format(delayed.finalize())) >>> # >>> self = kwcoco.CocoDataset.demo('shapes8') >>> delayed = self.delayed_load(gid) >>> print('delayed = {!r}'.format(delayed)) >>> print('delayed.finalize() = {!r}'.format(delayed.finalize()))
>>> crop = delayed.crop((slice(0, 3), slice(0, 3))) >>> crop.finalize()
>>> # TODO: should only select the "red" channel >>> self = kwcoco.CocoDataset.demo('shapes8') >>> delayed = self.delayed_load(gid, channels='r')
>>> import kwcoco >>> gid = 1 >>> # >>> self = kwcoco.CocoDataset.demo('vidshapes8-multispectral') >>> delayed = self.delayed_load(gid, channels='B1|B2', space='image') >>> print('delayed = {!r}'.format(delayed)) >>> delayed = self.delayed_load(gid, channels='B1|B2|B11', space='image') >>> print('delayed = {!r}'.format(delayed)) >>> delayed = self.delayed_load(gid, channels='B8|B1', space='video') >>> print('delayed = {!r}'.format(delayed))
>>> delayed = self.delayed_load(gid, channels='B8|foo|bar|B1', space='video') >>> print('delayed = {!r}'.format(delayed))
- load_image(gid_or_img, channels=None)[source]¶
Reads an image from disk and
- Parameters:
gid_or_img (int | dict) – image id or image dict
channels (str | None) – if specified, load data from auxiliary channels instead
- Returns:
the image
- Return type:
np.ndarray
Note
Prefer to use the CocoImage methods instead
- get_image_fpath(gid_or_img, channels=None)[source]¶
Returns the full path to the image
- Parameters:
gid_or_img (int | dict) – image id or image dict
channels (str | None) – if specified, return a path to data containing auxiliary channels instead
Note
Prefer to use the CocoImage methods instead
- Returns:
full path to the image
- Return type:
PathLike
- _get_img_auxiliary(gid_or_img, channels)[source]¶
returns the auxiliary dictionary for a specific channel
- get_auxiliary_fpath(gid_or_img, channels)[source]¶
Returns the full path to auxiliary data for an image
- Parameters:
gid_or_img (int | dict) – an image or its id
channels (str) – the auxiliary channel to load (e.g. disparity)
Note
Prefer to use the CocoImage methods instead
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes8', aux=True) >>> self.get_auxiliary_fpath(1, 'disparity')
- load_annot_sample(aid_or_ann, image=None, pad=None)[source]¶
Reads the chip of an annotation. Note this is much less efficient than using a sampler, but it doesn’t require disk cache.
Maybe deprecate?
- Parameters:
aid_or_int (int | dict) – annot id or dict
image (ArrayLike | None) – preloaded image (note: this process is inefficient unless image is specified)
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> sample = self.load_annot_sample(2, pad=100) >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.imshow(sample['im']) >>> kwplot.show_if_requested()

- _resolve_to_cid(id_or_name_or_dict)[source]¶
Ensures output is an category id
Note
this does not resolve aliases (yet), for that see _alias_to_cat
Todo
we could maintain an alias index to make this fast
- _resolve_to_kpcat(kp_identifier)[source]¶
Lookup a keypoint-category dict via its name or id
- Parameters:
kp_identifier (int | str | dict) – either the keypoint category name, alias, or its keypoint_category_id.
- Returns:
keypoint category dictionary
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes') >>> kpcat1 = self._resolve_to_kpcat(1) >>> kpcat2 = self._resolve_to_kpcat('left_eye') >>> assert kpcat1 is kpcat2 >>> import pytest >>> with pytest.raises(KeyError): >>> self._resolve_to_cat('human')
- _resolve_to_cat(cat_identifier)[source]¶
Lookup a coco-category dict via its name, alias, or id.
- Parameters:
cat_identifier (int | str | dict) – either the category name, alias, or its category_id.
- Raises:
KeyError – if the category doesn’t exist.
Note
If the index is not built, the method will work but may be slow.
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> cat = self._resolve_to_cat('human') >>> import pytest >>> assert self._resolve_to_cat(cat['id']) is cat >>> assert self._resolve_to_cat(cat) is cat >>> with pytest.raises(KeyError): >>> self._resolve_to_cat(32) >>> self.index.clear() >>> assert self._resolve_to_cat(cat['id']) is cat >>> with pytest.raises(KeyError): >>> self._resolve_to_cat(32)
- _alias_to_cat(alias_catname)[source]¶
Lookup a coco-category via its name or an “alias” name. In production code, use
_resolve_to_cat()instead.- Parameters:
alias_catname (str) – category name or alias
- Returns:
coco category dictionary
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> cat = self._alias_to_cat('human') >>> import pytest >>> with pytest.raises(KeyError): >>> self._alias_to_cat('person') >>> cat['alias'] = ['person'] >>> self._alias_to_cat('person') >>> cat['alias'] = 'person' >>> self._alias_to_cat('person') >>> assert self._alias_to_cat(None) is None
- category_graph()[source]¶
Construct a networkx category hierarchy
- Returns:
graph: a directed graph where category names are the nodes, supercategories define edges, and items in each category dict (e.g. category id) are added as node properties.
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> graph = self.category_graph() >>> assert 'astronaut' in graph.nodes() >>> assert 'keypoints' in graph.nodes['human']
- object_categories()[source]¶
Construct a consistent CategoryTree representation of object classes
- Returns:
category data structure
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> classes = self.object_categories() >>> print('classes = {}'.format(classes))
- keypoint_categories()[source]¶
Construct a consistent CategoryTree representation of keypoint classes
- Returns:
category data structure
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> classes = self.keypoint_categories() >>> print('classes = {}'.format(classes))
- _keypoint_category_names()[source]¶
Construct keypoint categories names.
Uses new-style if possible, otherwise this falls back on old-style.
- Returns:
names - list of keypoint category names
- Return type:
List[str]
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> names = self._keypoint_category_names() >>> print(names)
- class kwcoco.coco_dataset.MixinCocoConstructors[source]¶
Bases:
objectClassmethods for constructing CocoDataset objects
- classmethod coerce(key, sqlview=False, **kw)[source]¶
Attempt to transform the input into the intended CocoDataset.
- Parameters:
key – this can either be an instance of a CocoDataset, a string URI pointing to an on-disk dataset, or a special key for creating demodata.
sqlview (bool | str) – If truthy, will return the dataset as a cached sql view, which can be quicker to load and use in some instances. Can be given as a string, which sets the backend that is used: either sqlite or postgresql. Defaults to False.
**kw – passed to whatever constructor is chosen (if any)
- Returns:
AbstractCocoDataset | kwcoco.CocoDataset | kwcoco.CocoSqlDatabase
Example
>>> # test coerce for various input methods >>> import kwcoco >>> from kwcoco.coco_sql_dataset import assert_dsets_allclose >>> dct_dset = kwcoco.CocoDataset.coerce('special:shapes8') >>> copy1 = kwcoco.CocoDataset.coerce(dct_dset) >>> copy2 = kwcoco.CocoDataset.coerce(dct_dset.fpath) >>> assert assert_dsets_allclose(dct_dset, copy1) >>> assert assert_dsets_allclose(dct_dset, copy2) >>> # xdoctest: +REQUIRES(module:sqlalchemy) >>> sql_dset = dct_dset.view_sql() >>> copy3 = kwcoco.CocoDataset.coerce(sql_dset) >>> copy4 = kwcoco.CocoDataset.coerce(sql_dset.fpath) >>> assert assert_dsets_allclose(dct_dset, sql_dset) >>> assert assert_dsets_allclose(dct_dset, copy3) >>> assert assert_dsets_allclose(dct_dset, copy4)
- classmethod demo(key='photos', **kwargs)[source]¶
Create a toy coco dataset for testing and demo puposes
- Parameters:
key (str) – Either ‘photos’ (default), ‘shapes’, or ‘vidshapes’. There are also special sufixes that can control behavior.
Basic options that define which flavor of demodata to generate are: photos, shapes, and vidshapes. A numeric suffix e.g. vidshapes8 can be specified to indicate the size of the generated demo dataset. There are other special suffixes that are available. See the code in this function for explicit details on what is allowed.
TODO: better documentation for these demo datasets.
As a quick summary: the vidshapes key is the most robust and mature demodata set, and here are several useful variants of the vidshapes key.
vidshapes8 - the 8 suffix is the number of videos in this case.
vidshapes8-multispectral - generate 8 multispectral videos.
vidshapes8-msi - msi is an alias for multispectral.
vidshapes8-frames5 - generate 8 videos with 5 frames each.
vidshapes2-tracks5 - generate 2 videos with 5 tracks each.
(6) vidshapes2-speed0.1-frames7 - generate 2 videos with 7 frames where the objects move with with a speed of 0.1.
**kwargs – if key is shapes, these arguments are passed to toydata generation. The Kwargs section of this docstring documents a subset of the available options. For full details, see
demodata_toy_dset()andrandom_video_dset().- Notable options are:
bundle_dpath (PathLike): location to write the demo bundle fpath (PathLike): location to write the demo kwcoco file
- Kwargs:
image_size (Tuple[int, int]): width / height size of the images
- dpath (str | PathLike):
path to the directory where any generated demo bundles will be written to. Defaults to using kwcoco cache dir.
aux (bool): if True generates dummy auxiliary channels
- rng (int | RandomState | None):
random number generator or seed
verbose (int): verbosity mode. Defaults to 3.
Example
>>> # Basic demodata keys >>> print(CocoDataset.demo('photos', verbose=1)) >>> print(CocoDataset.demo('shapes', verbose=1)) >>> print(CocoDataset.demo('vidshapes', verbose=1)) >>> # Varaints of demodata keys >>> print(CocoDataset.demo('shapes8', verbose=0)) >>> print(CocoDataset.demo('shapes8-msi', verbose=0)) >>> print(CocoDataset.demo('shapes8-frames1-speed0.2-msi', verbose=0))
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('vidshapes5', num_frames=5, >>> verbose=0, rng=None) >>> dset = kwcoco.CocoDataset.demo('vidshapes5', num_frames=5, >>> num_tracks=4, verbose=0, rng=44) >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> pnums = kwplot.PlotNums(nSubplots=len(dset.index.imgs)) >>> fnum = 1 >>> for gx, gid in enumerate(dset.index.imgs.keys()): >>> canvas = dset.draw_image(gid=gid) >>> kwplot.imshow(canvas, pnum=pnums[gx], fnum=fnum) >>> #dset.show_image(gid=gid, pnum=pnums[gx]) >>> kwplot.show_if_requested()
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('vidshapes5-aux', num_frames=1, >>> verbose=0, rng=None)
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('vidshapes1-multispectral', num_frames=5, >>> verbose=0, rng=None) >>> # This is the first use-case of image names >>> assert len(dset.index.file_name_to_img) == 0, ( >>> 'the multispectral demo case has no "base" image') >>> assert len(dset.index.name_to_img) == len(dset.index.imgs) == 5 >>> dset.remove_images([1]) >>> assert len(dset.index.name_to_img) == len(dset.index.imgs) == 4 >>> dset.remove_videos([1]) >>> assert len(dset.index.name_to_img) == len(dset.index.imgs) == 0
- class kwcoco.coco_dataset.MixinCocoExtras[source]¶
Bases:
objectMisc functions for coco
- _dataset_id()[source]¶
A human interpretable name that can be used to uniquely identify the dataset.
Note
This function is currently subject to change.
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> print(self._dataset_id()) >>> self = kwcoco.CocoDataset.demo('vidshapes8') >>> print(self._dataset_id()) >>> self = kwcoco.CocoDataset() >>> print(self._dataset_id())
- _ensure_imgsize(workers=0, verbose=1, fail=False)[source]¶
Populate the imgsize field if it does not exist.
- Parameters:
workers (int) – number of workers for parallel processing.
verbose (int) – verbosity level
fail (bool) – if True, raises an exception if anything size fails to load.
- Returns:
- a list of “bad” image dictionaries where the size could
not be determined. Typically these are corrupted images and should be removed.
- Return type:
List[dict]
Example
>>> # Normal case >>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> bad_imgs = self._ensure_imgsize() >>> assert len(bad_imgs) == 0 >>> assert self.imgs[1]['width'] == 512 >>> assert self.imgs[2]['width'] == 328 >>> assert self.imgs[3]['width'] == 256
>>> # Fail cases >>> self = kwcoco.CocoDataset() >>> self.add_image('does-not-exist.jpg') >>> bad_imgs = self._ensure_imgsize() >>> assert len(bad_imgs) == 1 >>> import pytest >>> with pytest.raises(Exception): >>> self._ensure_imgsize(fail=True)
- _ensure_image_data(gids=None, verbose=1)[source]¶
Download data from “url” fields if specified.
- Parameters:
gids (List) – subset of images to download
- corrupted_images(check_aux=True, verbose=0, workers=0)[source]¶
Check for images that don’t exist or can’t be opened
- rename_categories(mapper, rebuild=True, merge_policy='ignore')[source]¶
Rename categories with a potentially coarser categorization.
- Parameters:
mapper (dict | Callable) – maps old names to new names. If multiple names are mapped to the same category, those categories will be merged.
merge_policy (str) – How to handle multiple categories that map to the same name. Can be update or ignore.
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self.rename_categories({'astronomer': 'person', >>> 'astronaut': 'person', >>> 'mouth': 'person', >>> 'helmet': 'hat'}) >>> assert 'hat' in self.name_to_cat >>> assert 'helmet' not in self.name_to_cat >>> # Test merge case >>> self = kwcoco.CocoDataset.demo() >>> mapper = { >>> 'helmet': 'rocket', >>> 'astronomer': 'rocket', >>> 'human': 'rocket', >>> 'mouth': 'helmet', >>> 'star': 'gas' >>> } >>> self.rename_categories(mapper)
- _aspycoco()[source]¶
Converts to the official pycocotools.coco.COCO object
Todo
[ ] Maybe expose as a public API?
- reroot(new_root=None, old_prefix=None, new_prefix=None, absolute=False, check=True, safe=True, verbose=1)[source]¶
Modify the prefix of the image/data paths onto a new image/data root.
- Parameters:
new_root (str | PathLike | None) – New image root. If unspecified the current
self.bundle_dpathis used. If old_prefix and new_prefix are unspecified, they will attempt to be determined based on the current root (which assumes the file paths exist at that root) and this new root. Defaults to None.old_prefix (str | None) – If specified, removes this prefix from file names. This also prevents any inferences that might be made via “new_root”. Defaults to None.
new_prefix (str | None) – If specified, adds this prefix to the file names. This also prevents any inferences that might be made via “new_root”. Defaults to None.
absolute (bool) – if True, file names are stored as absolute paths, otherwise they are relative to the new image root. Defaults to False.
check (bool) – if True, checks that the images all exist. Defaults to True.
safe (bool) – if True, does not overwrite values until all checks pass. Defaults to True.
verbose (int) – verbosity level, default=0.
CommandLine
xdoctest -m kwcoco.coco_dataset MixinCocoExtras.reroot
Todo
[ ] Incorporate maximum ordered subtree embedding?
Example
>>> # xdoctest: +REQUIRES(module:rich) >>> import kwcoco >>> import ubelt as ub >>> import rich >>> def report(dset): >>> gid = 1 >>> abs_fpath = ub.Path(dset.get_image_fpath(gid)) >>> rel_fpath = dset.index.imgs[gid]['file_name'] >>> color = 'green' if abs_fpath.exists() else 'red' >>> print(ub.color_text(f'abs_fpath = {abs_fpath!r}', color)) >>> print(f'rel_fpath = {rel_fpath!r}') >>> dset = self = kwcoco.CocoDataset.demo() >>> # Change base relative directory >>> bundle_dpath = ub.expandpath('~') >>> rich.print('ORIG self.imgs = {}'.format(ub.urepr(self.imgs, nl=1))) >>> rich.print('ORIG dset.bundle_dpath = {!r}'.format(dset.bundle_dpath)) >>> rich.print('NEW(1) bundle_dpath = {!r}'.format(bundle_dpath)) >>> # Test relative reroot >>> rich.print('[blue] --- 1. RELATIVE REROOT ---') >>> self.reroot(bundle_dpath, verbose=3) >>> report(self) >>> rich.print('NEW(1) self.imgs = {}'.format(ub.urepr(self.imgs, nl=1))) >>> if not ub.WIN32: >>> assert self.imgs[1]['file_name'].startswith('.cache') >>> # Test absolute reroot >>> rich.print('[blue] --- 2. ABSOLUTE REROOT ---') >>> self.reroot(absolute=True, verbose=3) >>> rich.print('NEW(2) self.imgs = {}'.format(ub.urepr(self.imgs, nl=1))) >>> assert self.imgs[1]['file_name'].startswith(bundle_dpath)
>>> # Switch back to relative paths >>> rich.print('[blue] --- 3. ABS->REL REROOT ---') >>> self.reroot() >>> rich.print('NEW(3) self.imgs = {}'.format(ub.urepr(self.imgs, nl=1))) >>> if not ub.WIN32: >>> assert self.imgs[1]['file_name'].startswith('.cache')
Example
>>> # demo with auxiliary data >>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes8', aux=True) >>> bundle_dpath = ub.expandpath('~') >>> print(self.imgs[1]['file_name']) >>> print(self.imgs[1]['auxiliary'][0]['file_name']) >>> self.reroot(new_root=bundle_dpath) >>> print(self.imgs[1]['file_name']) >>> print(self.imgs[1]['auxiliary'][0]['file_name']) >>> if not ub.WIN32: >>> assert self.imgs[1]['file_name'].startswith('.cache') >>> assert self.imgs[1]['auxiliary'][0]['file_name'].startswith('.cache')
- property data_root¶
In the future we will deprecate data_root for bundle_dpath
- property img_root¶
In the future we will deprecate img_root for bundle_dpath
- property data_fpath¶
data_fpath is an alias of fpath
- class kwcoco.coco_dataset.MixinCocoHashing[source]¶
Bases:
objectMixin for creating and maintaining hashids (i.e. content identifiers)
- _build_hashid(hash_pixels=False, verbose=0)[source]¶
Construct a hash that uniquely identifies the state of this dataset.
- Parameters:
hash_pixels (bool) – If False the image data is not included in the hash, which can speed up computation, but is not 100% robust. Defaults to False.
verbose (int) – verbosity level
- Returns:
the hashid
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self._build_hashid(hash_pixels=True, verbose=3) ... >>> # Shorten hashes for readability >>> import ubelt as ub >>> walker = ub.IndexableWalker(self.hashid_parts) >>> for path, val in walker: >>> if isinstance(val, str): >>> walker[path] = val[0:8] >>> # Note: this may change in different versions of kwcoco >>> print('self.hashid_parts = ' + ub.urepr(self.hashid_parts)) >>> print('self.hashid = {!r}'.format(self.hashid[0:8])) self.hashid_parts = { 'annotations': { 'json': 'c1d1b9c3', 'num': 11, }, 'images': { 'pixels': '88e37cc3', 'json': '9b8e8be3', 'num': 3, }, 'categories': { 'json': '82d22e00', 'num': 8, }, } self.hashid = 'bf69bf15'
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self._build_hashid(hash_pixels=True, verbose=3) >>> self.hashid_parts >>> # Test that when we modify the dataset only the relevant >>> # hashid parts are recomputed. >>> orig = self.hashid_parts['categories']['json'] >>> self.add_category('foobar') >>> assert 'categories' not in self.hashid_parts >>> self.hashid_parts >>> self.hashid_parts['images']['json'] = 'should not change' >>> self._build_hashid(hash_pixels=True, verbose=3) >>> assert self.hashid_parts['categories']['json'] >>> assert self.hashid_parts['categories']['json'] != orig >>> assert self.hashid_parts['images']['json'] == 'should not change'
- _invalidate_hashid(parts=None)[source]¶
Called whenever the coco dataset is modified. It is possible to specify which parts were modified so unmodified parts can be reused next time the hash is constructed.
Todo
[ ] Rename to _notify_modification — or something like that
- _cached_hashid()[source]¶
Under Construction.
The idea is to cache the hashid when we are sure that the dataset was loaded from a file and has not been modified. We can record the modification time of the file (because we know it hasn’t changed in memory), and use that as a key to the cache. If the modification time on the file is different than the one recorded in the cache, we know the cache could be invalid, so we recompute the hashid.
Todo
[ ] This is reasonably stable, elevate this to a public API function.
- class kwcoco.coco_dataset.MixinCocoObjects[source]¶
Bases:
objectExpose methods to construct object lists / groups.
This is an alternative vectorized ORM-like interface to the coco dataset
- annots(annot_ids=None, image_id=None, track_id=None, video_id=None, trackid=None, aids=None, gid=None)[source]¶
Return vectorized annotation objects
- Parameters:
annot_ids (List[int] | None) – annotation ids to reference, if unspecified all annotations are returned. An alias is “aids”, which may be removed in the future.
image_id (int | None) – return all annotations that belong to this image id. Mutually exclusive with other arguments. An alias is “gids”, which may be removed in the future.
track_id (int | None) – return all annotations that belong to this track. mutually exclusive with other arguments. An alias is “trackid”, which may be removed in the future.
video_id (int | None) – return all annotations that belong to this video. mutually exclusive with other arguments.
- Returns:
vectorized annotation object
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> annots = self.annots() >>> print(annots) <Annots(num=11)> >>> sub_annots = annots.take([1, 2, 3]) >>> print(sub_annots) <Annots(num=3)> >>> print(ub.urepr(sub_annots.get('bbox', None))) [ [350, 5, 130, 290], None, None, ]
- images(image_ids=None, video_id=None, names=None, gids=None, vidid=None)[source]¶
Return vectorized image objects
- Parameters:
image_ids (List[int] | None) – image ids to reference, if unspecified all images are returned. An alias is gids.
video_id (int | None) – returns all images that belong to this video id. mutually exclusive with image_ids arg.
names (List[str] | None) – lookup images by their names.
- Returns:
vectorized image object
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> images = self.images() >>> print(images) <Images(num=3)>
>>> self = kwcoco.CocoDataset.demo('vidshapes2') >>> video_id = 1 >>> images = self.images(video_id=video_id) >>> assert all(v == video_id for v in images.lookup('video_id')) >>> print(images) <Images(num=2)>
- categories(category_ids=None, cids=None)[source]¶
Return vectorized category objects
- Parameters:
category_ids (List[int] | None) – category ids to reference, if unspecified all categories are returned. The cids argument is an alias.
- Returns:
vectorized category object
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> categories = self.categories() >>> print(categories) <Categories(num=8)>
- videos(video_ids=None, names=None, vidids=None)[source]¶
Return vectorized video objects
- Parameters:
video_ids (List[int] | None) – video ids to reference, if unspecified all videos are returned. The vidids argument is an alias. Mutually exclusive with other args.
names (List[str] | None) – lookup videos by their name. Mutually exclusive with other args.
- Returns:
vectorized video object
- Return type:
Todo
- [ ] This conflicts with what should be the property that
should redirect to
index.videos, we should resolve this somehow. E.g. all other main members of the index (anns, imgs, cats) have a toplevel dataset property, we don’t have one for videos because the name we would pick conflicts with this.
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('vidshapes2') >>> videos = self.videos() >>> print(videos) >>> videos.lookup('name') >>> videos.lookup('id') >>> print('videos.objs = {}'.format(ub.urepr(videos.objs[0:2], nl=1)))
- tracks(track_ids=None, names=None)[source]¶
Return vectorized track objects
- Parameters:
track_ids (List[int] | None) – track ids to reference, if unspecified all tracks are returned.
names (List[str] | None) – lookup tracks by their name. Mutually exclusive with other args.
- Returns:
vectorized video object
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('vidshapes2') >>> tracks = self.tracks() >>> print(tracks) >>> tracks.lookup('name') >>> tracks.lookup('id') >>> print('tracks.objs = {}'.format(ub.urepr(tracks.objs[0:2], nl=1)))
- class kwcoco.coco_dataset.MixinCocoStats[source]¶
Bases:
objectMethods for getting stats about the dataset
- property n_annots¶
The number of annotations in the dataset
- property n_images¶
The number of images in the dataset
- property n_cats¶
The number of categories in the dataset
- property n_tracks¶
The number of tracks in the dataset
- property n_videos¶
The number of videos in the dataset
- category_annotation_frequency()[source]¶
Reports the number of annotations of each category
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> hist = self.category_annotation_frequency() >>> print(ub.urepr(hist)) { 'astroturf': 0, 'human': 0, 'astronaut': 1, 'astronomer': 1, 'helmet': 1, 'rocket': 1, 'mouth': 2, 'star': 5, }
- conform(**config)[source]¶
Make the COCO file conform a stricter spec, infers attibutes where possible.
Corresponds to the
kwcoco conformCLI tool.- KWArgs:
**config :
pycocotools_info (default=True): returns info required by pycocotools
ensure_imgsize (default=True): ensure image size is populated
mmlab (default=False): if True tries to convert data to be compatible with open-mmlab tooling.
legacy (default=False): if True tries to convert data structures to items compatible with the original pycocotools spec
workers (int): number of parallel jobs for IO tasks
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('shapes8') >>> dset.index.imgs[1].pop('width') >>> dset.conform(legacy=True) >>> assert 'width' in dset.index.imgs[1] >>> assert 'area' in dset.index.anns[1]
- validate(**config)[source]¶
Performs checks on this coco dataset.
Corresponds to the
kwcoco validateCLI tool.- Parameters:
**config – schema (default=True): if True, validate the json-schema
unique (default=True): if True, validate unique secondary keys
missing (default=True): if True, validate registered files exist
corrupted (default=False): if True, validate data in registered files
channels (default=True): if True, validate that channels in auxiliary/asset items are all unique.
require_relative (default=False): if True, causes validation to fail if paths are non-portable, i.e. all paths must be relative to the bundle directory. if>0, paths must be relative to bundle root. if>1, paths must be inside bundle root.
img_attrs (default=’warn’): if truthy, check that image attributes contain width and height entries. If ‘warn’, then warn if they do not exist. If ‘error’, then fail.
verbose (default=1): verbosity flag
workers (int): number of workers for parallel checks. defaults to 0
fastfail (default=False): if True raise errors immediately
- Returns:
- result containing keys -
status (bool): False if any errors occurred errors (List[str]): list of all error messages missing (List): List of any missing images corrupted (List): List of any corrupted images
- Return type:
- SeeAlso:
_check_integrity()- performs internal checks
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> import pytest >>> with pytest.warns(UserWarning): >>> result = self.validate() >>> assert not result['errors'] >>> assert result['warnings']
- stats(**kwargs)[source]¶
Compute summary statistics to describe the dataset at a high level
This function corresponds to
kwcoco.cli.coco_stats.- KWargs:
basic(bool): return basic stats’, default=True extended(bool): return extended stats’, default=True catfreq(bool): return category frequency stats’, default=True boxes(bool): return bounding box stats’, default=False
annot_attrs(bool): return annotation attribute information’, default=True image_attrs(bool): return image attribute information’, default=True
- Returns:
info
- Return type:
- basic_stats()[source]¶
Reports number of images, annotations, and categories.
- SeeAlso:
kwcoco.coco_dataset.MixinCocoStats.basic_stats()kwcoco.coco_dataset.MixinCocoStats.extended_stats()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> print(ub.urepr(self.basic_stats())) { 'n_anns': 11, 'n_imgs': 3, 'n_videos': 0, 'n_cats': 8, 'n_tracks': 0, }
>>> from kwcoco.demo.toydata_video import random_video_dset >>> dset = random_video_dset(render=True, num_frames=2, num_tracks=10, rng=0) >>> print(ub.urepr(dset.basic_stats())) { 'n_anns': 20, 'n_imgs': 2, 'n_videos': 1, 'n_cats': 3, 'n_tracks': 10, }
- extended_stats()[source]¶
Reports number of images, annotations, and categories.
- SeeAlso:
kwcoco.coco_dataset.MixinCocoStats.basic_stats()kwcoco.coco_dataset.MixinCocoStats.extended_stats()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> print(ub.urepr(self.extended_stats()))
- boxsize_stats(anchors=None, perclass=True, gids=None, aids=None, verbose=0, clusterkw={}, statskw={})[source]¶
Compute statistics about bounding box sizes.
Also computes anchor boxes using kmeans if
anchorsis specified.- Parameters:
anchors (int | None) – if specified also computes box anchors via KMeans clustering
perclass (bool) – if True also computes stats for each category
gids (List[int] | None) – if specified only compute stats for these image ids. Defaults to None.
aids (List[int] | None) – if specified only compute stats for these annotation ids. Defaults to None.
verbose (int) – verbosity level
clusterkw (dict) – kwargs for
sklearn.cluster.KMeansused if computing anchors.statskw (dict) – kwargs for
kwarray.stats_dict()
- Returns:
Stats are returned in width-height format.
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes32') >>> infos = self.boxsize_stats(anchors=4, perclass=False) >>> print(ub.urepr(infos, nl=-1, precision=2))
>>> infos = self.boxsize_stats(gids=[1], statskw=dict(median=True)) >>> print(ub.urepr(infos, nl=-1, precision=2))
- find_representative_images(gids=None)[source]¶
Find images that have a wide array of categories.
Attempt to find the fewest images that cover all categories using images that contain both a large and small number of annotations.
- Parameters:
gids (None | List) – Subset of image ids to consider when finding representative images. Uses all images if unspecified.
- Returns:
list of image ids determined to be representative
- Return type:
List
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> gids = self.find_representative_images() >>> print('gids = {!r}'.format(gids)) >>> gids = self.find_representative_images([3]) >>> print('gids = {!r}'.format(gids))
>>> self = kwcoco.CocoDataset.demo('shapes8') >>> gids = self.find_representative_images() >>> print('gids = {!r}'.format(gids)) >>> valid = {7, 1} >>> gids = self.find_representative_images(valid) >>> assert valid.issuperset(gids) >>> print('gids = {!r}'.format(gids))
- class kwcoco.coco_dataset.MixinCocoDraw[source]¶
Bases:
objectMatplotlib / display functionality
- draw_image(gid, channels=None)[source]¶
Use kwimage to draw all annotations on an image and return the pixels as a numpy array.
- Parameters:
gid (int) – image id to draw
channels (kwcoco.ChannelSpec) – the channel to draw on
- Returns:
canvas
- Return type:
ndarray
- SeeAlso
kwcoco.coco_dataset.MixinCocoDraw.draw_image()kwcoco.coco_dataset.MixinCocoDraw.show_image()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes8') >>> self.draw_image(1) >>> # Now you can dump the annotated image to disk / whatever >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.imshow(canvas)
- show_image(gid=None, aids=None, aid=None, channels=None, setlim=None, **kwargs)[source]¶
Use matplotlib to show an image with annotations overlaid
- Parameters:
gid (int | None) – image id to show
aids (list | None) – aids to highlight within the image
aid (int | None) – a specific aid to focus on. If gid is not give, look up gid based on this aid.
setlim (None | str) – if ‘image’ sets the limit to the image extent
**kwargs – show_annots, show_aid, show_catname, show_kpname, show_segmentation, title, show_gid, show_filename, show_boxes,
- SeeAlso
kwcoco.coco_dataset.MixinCocoDraw.draw_image()kwcoco.coco_dataset.MixinCocoDraw.show_image()
CommandLine
xdoctest -m kwcoco.coco_dataset MixinCocoDraw.show_image --show
Example
>>> # xdoctest: +REQUIRES(module:kwplot) >>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('vidshapes8-msi') >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> # xdoctest: -REQUIRES(--show) >>> dset.show_image(gid=1, channels='B8') >>> # xdoctest: +REQUIRES(--show) >>> kwplot.show_if_requested()
- class kwcoco.coco_dataset.MixinCocoAddRemove[source]¶
Bases:
objectMixin functions to dynamically add / remove annotations images and categories while maintaining lookup indexes.
- add_video(name, id=None, **kw)[source]¶
Register a new video with the dataset
- Parameters:
name (str) – Unique name for this video.
id (None | int) – ADVANCED. Force using this image id.
**kw – stores arbitrary key/value pairs in this new video
- Returns:
the video id assigned to the new video
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset() >>> print('self.index.videos = {}'.format(ub.urepr(self.index.videos, nl=1))) >>> print('self.index.imgs = {}'.format(ub.urepr(self.index.imgs, nl=1))) >>> print('self.index.vidid_to_gids = {!r}'.format(self.index.vidid_to_gids))
>>> vidid1 = self.add_video('foo', id=3) >>> vidid2 = self.add_video('bar') >>> vidid3 = self.add_video('baz') >>> print('self.index.videos = {}'.format(ub.urepr(self.index.videos, nl=1))) >>> print('self.index.imgs = {}'.format(ub.urepr(self.index.imgs, nl=1))) >>> print('self.index.vidid_to_gids = {!r}'.format(self.index.vidid_to_gids))
>>> gid1 = self.add_image('foo1.jpg', video_id=vidid1, frame_index=0) >>> gid2 = self.add_image('foo2.jpg', video_id=vidid1, frame_index=1) >>> gid3 = self.add_image('foo3.jpg', video_id=vidid1, frame_index=2) >>> gid4 = self.add_image('bar1.jpg', video_id=vidid2, frame_index=0) >>> print('self.index.videos = {}'.format(ub.urepr(self.index.videos, nl=1))) >>> print('self.index.imgs = {}'.format(ub.urepr(self.index.imgs, nl=1))) >>> print('self.index.vidid_to_gids = {!r}'.format(self.index.vidid_to_gids))
>>> self.remove_images([gid2]) >>> print('self.index.vidid_to_gids = {!r}'.format(self.index.vidid_to_gids))
- add_image(file_name=None, id=None, **kw)[source]¶
Register a new image with the dataset
- Parameters:
file_name (str | None) – relative or absolute path to image. if not given, then “name” must be specified and we will expect that “auxiliary” assets are eventually added.
id (None | int) – ADVANCED. Force using this image id.
name (str) – a unique key to identify this image
width (int) – base width of the image
height (int) – base height of the image
channels (ChannelSpec) – specification of base channels. Only relevant if file_name is given.
auxiliary (List[Dict]) – specification of auxiliary assets. See
CocoImage.add_asset()for detailsvideo_id (int) – id of parent video, if applicable
frame_index (int) – frame index in parent video
timestamp (number | str) – timestamp of frame index
warp_img_to_vid (Dict) – this transform is used to align the image to a video if it belongs to one.
**kw – stores arbitrary key/value pairs in this new image
- Returns:
the image id assigned to the new image
- Return type:
- SeeAlso:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> import kwimage >>> gname = kwimage.grab_test_image_fpath('paraview') >>> gid = self.add_image(gname) >>> assert self.imgs[gid]['file_name'] == gname
- add_asset(gid, file_name=None, channels=None, **kwargs)[source]¶
Adds an auxiliary / asset item to the image dictionary.
- Parameters:
gid (int) – The image id to add the auxiliary/asset item to.
file_name (str | None) – The name of the file relative to the bundle directory. If unspecified, imdata must be given.
channels (str | kwcoco.FusedChannelSpec) – The channel code indicating what each of the bands represents. These channels should be disjoint wrt to the existing data in this image (this is not checked).
**kwargs – See
CocoImage.add_asset()for more details
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset() >>> gid = dset.add_image(name='my_image_name', width=200, height=200) >>> dset.add_asset(gid, 'path/fake_B0.tif', channels='B0', width=200, >>> height=200, warp_aux_to_img={'scale': 1.0})
- add_auxiliary_item(gid, file_name=None, channels=None, **kwargs)¶
Adds an auxiliary / asset item to the image dictionary.
- Parameters:
gid (int) – The image id to add the auxiliary/asset item to.
file_name (str | None) – The name of the file relative to the bundle directory. If unspecified, imdata must be given.
channels (str | kwcoco.FusedChannelSpec) – The channel code indicating what each of the bands represents. These channels should be disjoint wrt to the existing data in this image (this is not checked).
**kwargs – See
CocoImage.add_asset()for more details
Example
>>> import kwcoco >>> dset = kwcoco.CocoDataset() >>> gid = dset.add_image(name='my_image_name', width=200, height=200) >>> dset.add_asset(gid, 'path/fake_B0.tif', channels='B0', width=200, >>> height=200, warp_aux_to_img={'scale': 1.0})
- add_annotation(image_id, category_id=None, bbox=NoParam, segmentation=NoParam, keypoints=NoParam, id=None, track_id=None, **kw)[source]¶
Register a new annotation with the dataset
- Parameters:
image_id (int) – image_id the annotation is added to.
category_id (int | None) – category_id for the new annotation
bbox (list | kwimage.Boxes) – bounding box in xywh format
segmentation (Dict | List | Any) – keypoints in some accepted format, see
kwimage.Mask.to_coco()andkwimage.MultiPolygon.to_coco(). Extended types: MaskLike | MultiPolygonLike.keypoints (Any) – keypoints in some accepted format, see
kwimage.Keypoints.to_coco(). Extended types: KeypointsLike.id (None | int) – Force using this annotation id. Typically you should NOT specify this. A new unused id will be chosen and returned.
track_id (int | str | None) – Some value used to associate annotations that belong to the same “track”. In the future we may remove support for strings.
**kw – stores arbitrary key/value pairs in this new image, Common respected key/values include but are not limited to the following: score : float prob : List[float] weight (float): a weight, usually used to indicate if a ground truth annotation is difficult / important. This generalizes standard “is_hard” or “ignore” attributes in other formats. caption (str): a text caption for this annotation
- Returns:
the annotation id assigned to the new annotation
- Return type:
- SeeAlso:
kwcoco.coco_dataset.MixinCocoAddRemove.add_annotation()kwcoco.coco_dataset.MixinCocoAddRemove.add_annotations()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> image_id = 1 >>> cid = 1 >>> bbox = [10, 10, 20, 20] >>> aid = self.add_annotation(image_id, cid, bbox) >>> assert self.anns[aid]['bbox'] == bbox
Example
>>> import kwimage >>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> new_det = kwimage.Detections.random(1, segmentations=True, keypoints=True) >>> # kwimage datastructures have methods to convert to coco recognized formats >>> new_ann_data = list(new_det.to_coco(style='new'))[0] >>> image_id = 1 >>> aid = self.add_annotation(image_id, **new_ann_data) >>> # Lookup the annotation we just added >>> ann = self.index.anns[aid] >>> print('ann = {}'.format(ub.urepr(ann, nl=-2)))
Example
>>> # Attempt to add annot without a category or bbox >>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> image_id = 1 >>> aid = self.add_annotation(image_id) >>> assert None in self.index.cid_to_aids
Example
>>> # Attempt to add annot using various styles of kwimage structures >>> import kwcoco >>> import kwimage >>> self = kwcoco.CocoDataset.demo() >>> image_id = 1 >>> #-- >>> kw = {} >>> kw['segmentation'] = kwimage.Polygon.random() >>> kw['keypoints'] = kwimage.Points.random() >>> aid = self.add_annotation(image_id, **kw) >>> ann = self.index.anns[aid] >>> print('ann = {}'.format(ub.urepr(ann, nl=2))) >>> #-- >>> kw = {} >>> kw['segmentation'] = kwimage.Mask.random() >>> aid = self.add_annotation(image_id, **kw) >>> ann = self.index.anns[aid] >>> assert ann.get('segmentation', None) is not None >>> print('ann = {}'.format(ub.urepr(ann, nl=2))) >>> #-- >>> kw = {} >>> kw['segmentation'] = kwimage.Mask.random().to_array_rle() >>> aid = self.add_annotation(image_id, **kw) >>> ann = self.index.anns[aid] >>> assert ann.get('segmentation', None) is not None >>> print('ann = {}'.format(ub.urepr(ann, nl=2))) >>> #-- >>> kw = {} >>> kw['segmentation'] = kwimage.Polygon.random().to_coco() >>> kw['keypoints'] = kwimage.Points.random().to_coco() >>> aid = self.add_annotation(image_id, **kw) >>> ann = self.index.anns[aid] >>> assert ann.get('segmentation', None) is not None >>> assert ann.get('keypoints', None) is not None >>> print('ann = {}'.format(ub.urepr(ann, nl=2)))
- add_category(name, supercategory=None, id=None, **kw)[source]¶
Register a new category with the dataset
- Parameters:
name (str) – name of the new category
supercategory (str | None) – parent of this category
id (int | None) – use this category id, if it was not taken
**kw – stores arbitrary key/value pairs in this new image
- Returns:
the category id assigned to the new category
- Return type:
- SeeAlso:
kwcoco.coco_dataset.MixinCocoAddRemove.add_category()kwcoco.coco_dataset.MixinCocoAddRemove.ensure_category()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> prev_n_cats = self.n_cats >>> cid = self.add_category('dog', supercategory='object') >>> assert self.cats[cid]['name'] == 'dog' >>> assert self.n_cats == prev_n_cats + 1 >>> import pytest >>> with pytest.raises(ValueError): >>> self.add_category('dog', supercategory='object')
- add_track(name, id=None, **kw)[source]¶
Register a new track with the dataset
- Parameters:
name (str) – name of the new track
id (int | None) – use this track id, if it was not taken
**kw – stores arbitrary key/value pairs in this new image
- Returns:
the track id assigned to the new track
- Return type:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> prev_n_tracks = self.n_tracks >>> track_id = self.add_track('dog') >>> assert self.index.tracks[track_id]['name'] == 'dog' >>> assert self.n_tracks == prev_n_tracks + 1 >>> import pytest >>> with pytest.raises(ValueError): >>> self.add_track('dog')
- ensure_video(name, id=None, **kw)[source]¶
Register a video if it is new or returns an existing id.
Like
kwcoco.coco_dataset.MixinCocoAddRemove.add_video(), but returns the existing video id if it already exists instead of failing. In this case all metadata is ignored.- Parameters:
file_name (str) – relative or absolute path to video
id (None | int) – ADVANCED. Force using this video id.
**kw – stores arbitrary key/value pairs in this new video
- Returns:
the existing or new video id
- Return type:
- SeeAlso:
kwcoco.coco_dataset.MixinCocoAddRemove.add_video()kwcoco.coco_dataset.MixinCocoAddRemove.ensure_video()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> id1 = self.ensure_video('video1') >>> id2 = self.ensure_video('video1') >>> assert id1 == id2
- ensure_track(name, id=None, **kw)[source]¶
Register a track if it is new or returns an existing id.
Like
kwcoco.coco_dataset.MixinCocoAddRemove.add_track(), but returns the existing track id if it already exists instead of failing. In this case all metadata is ignored.- Parameters:
file_name (str) – relative or absolute path to track
id (None | int) – ADVANCED. Force using this track id.
**kw – stores arbitrary key/value pairs in this new track
- Returns:
the existing or new track id
- Return type:
- SeeAlso:
kwcoco.coco_dataset.MixinCocoAddRemove.add_track()kwcoco.coco_dataset.MixinCocoAddRemove.ensure_track()
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> track_id1 = self.ensure_track('dog') >>> track_id2 = self.ensure_track('dog') >>> assert track_id1 == track_id2
- ensure_image(file_name, id=None, **kw)[source]¶
Register an image if it is new or returns an existing id.
Like
kwcoco.coco_dataset.MixinCocoAddRemove.add_image(), but returns the existing image id if it already exists instead of failing. In this case all metadata is ignored.- Parameters:
file_name (str) – relative or absolute path to image
id (None | int) – ADVANCED. Force using this image id.
**kw – stores arbitrary key/value pairs in this new image
- Returns:
the existing or new image id
- Return type:
- ensure_category(name, supercategory=None, id=None, **kw)[source]¶
Register a category if it is new or returns an existing id.
Like
kwcoco.coco_dataset.MixinCocoAddRemove.add_category(), but returns the existing category id if it already exists instead of failing. In this case all metadata is ignored.- Returns:
the existing or new category id
- Return type:
- add_annotations(anns)[source]¶
Faster less-safe multi-item alternative to add_annotation.
We assume the annotations are well formatted in kwcoco compliant dictionaries, including the “id” field. No validation checks are made when calling this function.
- Parameters:
anns (List[Dict]) – list of annotation dictionaries
- SeeAlso:
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> anns = [self.anns[aid] for aid in [2, 3, 5, 7]] >>> self.remove_annotations(anns) >>> assert self.n_annots == 7 and self._check_integrity() >>> self.add_annotations(anns) >>> assert self.n_annots == 11 and self._check_integrity()
- add_images(imgs)[source]¶
Faster less-safe multi-item alternative
We assume the images are well formatted in kwcoco compliant dictionaries, including the “id” field. No validation checks are made when calling this function.
Note
THIS FUNCTION WAS DESIGNED FOR SPEED, AS SUCH IT DOES NOT CHECK IF THE IMAGE-IDs or FILE_NAMES ARE DUPLICATED AND WILL BLINDLY ADD DATA EVEN IF IT IS BAD. THE SINGLE IMAGE VERSION IS SLOWER BUT SAFER.
- Parameters:
imgs (List[Dict]) – list of image dictionaries
- SeeAlso:
kwcoco.coco_dataset.MixinCocoAddRemove.add_image()kwcoco.coco_dataset.MixinCocoAddRemove.add_images()kwcoco.coco_dataset.MixinCocoAddRemove.ensure_image()
Example
>>> import kwcoco >>> imgs = kwcoco.CocoDataset.demo().dataset['images'] >>> self = kwcoco.CocoDataset() >>> self.add_images(imgs) >>> assert self.n_images == 3 and self._check_integrity()
- clear_images()[source]¶
Removes all images and annotations (but not categories)
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self.clear_images() >>> print(ub.urepr(self.basic_stats(), nobr=1, nl=0, si=1)) n_anns: 0, n_imgs: 0, n_videos: 0, n_cats: 8, n_tracks: 0
- clear_annotations()[source]¶
Removes all annotations and tracks (but not images and categories)
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self.clear_annotations() >>> print(ub.urepr(self.basic_stats(), nobr=1, nl=0, si=1)) n_anns: 0, n_imgs: 3, n_videos: 0, n_cats: 8, n_tracks: 0
- remove_annotation(aid_or_ann)[source]¶
Remove a single annotation from the dataset
If you have multiple annotations to remove its more efficient to remove them in batch with
kwcoco.coco_dataset.MixinCocoAddRemove.remove_annotations()Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> aids_or_anns = [self.anns[2], 3, 4, self.anns[1]] >>> self.remove_annotations(aids_or_anns) >>> assert len(self.dataset['annotations']) == 7 >>> self._check_integrity()
- remove_annotations(aids_or_anns, verbose=0, safe=True)[source]¶
Remove multiple annotations from the dataset.
- Parameters:
anns_or_aids (List) – list of annotation dicts or ids
safe (bool) – if True, we perform checks to remove duplicates and non-existing identifiers. Defaults to True.
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> prev_n_annots = self.n_annots >>> aids_or_anns = [self.anns[2], 3, 4, self.anns[1]] >>> self.remove_annotations(aids_or_anns) # xdoc: +IGNORE_WANT {'annotations': 4} >>> assert len(self.dataset['annotations']) == prev_n_annots - 4 >>> self._check_integrity()
- remove_categories(cat_identifiers, keep_annots=False, verbose=0, safe=True)[source]¶
Remove categories and all annotations in those categories.
Currently does not change any hierarchy information
- Parameters:
cat_identifiers (List) – list of category dicts, names, or ids
keep_annots (bool) – if True, keeps annotations, but removes category labels. Defaults to False.
safe (bool) – if True, we perform checks to remove duplicates and non-existing identifiers. Defaults to True.
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> cat_identifiers = [self.cats[1], 'rocket', 3] >>> self.remove_categories(cat_identifiers) >>> assert len(self.dataset['categories']) == 5 >>> self._check_integrity()
- remove_tracks(track_identifiers, keep_annots=False, verbose=0, safe=True)[source]¶
Remove tracks and all annotations in those tracks.
- Parameters:
track_identifiers (List) – list of track dicts, names, or ids
keep_annots (bool) – if True, keeps annotations, but removes tracks labels. Defaults to False.
safe (bool) – if True, we perform checks to remove duplicates and non-existing identifiers. Defaults to True.
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('vidshapes1') >>> for ann in self.dataset['annotations']: ... ann.pop('segmentation') ... ann.pop('keypoints') >>> print('self.dataset = {}'.format(ub.urepr(self.dataset, nl=2))) >>> track_identifiers = [2] >>> assert len(self.dataset['tracks']) == 2 >>> self.remove_tracks(track_identifiers) >>> print('self.dataset = {}'.format(ub.urepr(self.dataset, nl=2))) >>> assert len(self.dataset['tracks']) == 1 >>> self._check_integrity()
- remove_images(gids_or_imgs, verbose=0, safe=True)[source]¶
Remove images and any annotations contained by them
- Parameters:
gids_or_imgs (List) – list of image dicts, names, or ids
safe (bool) – if True, we perform checks to remove duplicates and non-existing identifiers.
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> assert len(self.dataset['images']) == 3 >>> gids_or_imgs = [self.imgs[2], 'astro.png'] >>> self.remove_images(gids_or_imgs) # xdoc: +IGNORE_WANT {'annotations': 11, 'images': 2} >>> assert len(self.dataset['images']) == 1 >>> self._check_integrity() >>> gids_or_imgs = [3] >>> self.remove_images(gids_or_imgs) >>> assert len(self.dataset['images']) == 0 >>> self._check_integrity()
- remove_videos(vidids_or_videos, verbose=0, safe=True)[source]¶
Remove videos and any images / annotations contained by them
- Parameters:
vidids_or_videos (List) – list of video dicts, names, or ids
safe (bool) – if True, we perform checks to remove duplicates and non-existing identifiers.
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('vidshapes8') >>> assert len(self.dataset['videos']) == 8 >>> vidids_or_videos = [self.dataset['videos'][0]['id']] >>> self.remove_videos(vidids_or_videos) # xdoc: +IGNORE_WANT {'annotations': 4, 'images': 2, 'videos': 1} >>> assert len(self.dataset['videos']) == 7 >>> self._check_integrity()
- remove_annotation_keypoints(kp_identifiers)[source]¶
Removes all keypoints with a particular category
- Parameters:
kp_identifiers (List) – list of keypoint category dicts, names, or ids
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
- remove_keypoint_categories(kp_identifiers)[source]¶
Removes all keypoints of a particular category as well as all annotation keypoints with those ids.
- Parameters:
kp_identifiers (List) – list of keypoint category dicts, names, or ids
- Returns:
num_removed: information on the number of items removed
- Return type:
Dict
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('shapes', rng=0) >>> kp_identifiers = ['left_eye', 'mid_tip'] >>> remove_info = self.remove_keypoint_categories(kp_identifiers) >>> print('remove_info = {!r}'.format(remove_info)) >>> # FIXME: for whatever reason demodata generation is not determenistic when seeded >>> # assert remove_info == {'keypoint_categories': 2, 'annotation_keypoints': 16, 'reflection_ids': 1} >>> assert self._resolve_to_kpcat('right_eye')['reflection_id'] is None
- set_annotation_category(aid_or_ann, cid_or_cat)[source]¶
Sets the category of a single annotation
- Parameters:
aid_or_ann (dict | int) – annotation dict or id
cid_or_cat (dict | int) – category dict or id
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> old_freq = self.category_annotation_frequency() >>> aid_or_ann = aid = 2 >>> cid_or_cat = new_cid = self.ensure_category('kitten') >>> self.set_annotation_category(aid, new_cid) >>> new_freq = self.category_annotation_frequency() >>> print('new_freq = {}'.format(ub.urepr(new_freq, nl=1))) >>> print('old_freq = {}'.format(ub.urepr(old_freq, nl=1))) >>> assert sum(new_freq.values()) == sum(old_freq.values()) >>> assert new_freq['kitten'] == 1
- class kwcoco.coco_dataset.CocoIndex[source]¶
Bases:
objectFast lookup index for the COCO dataset with dynamic modification
- Variables:
imgs (Dict[int, dict]) – mapping between image ids and the image dictionaries
anns (Dict[int, dict]) – mapping between annotation ids and the annotation dictionaries
cats (Dict[int, dict]) – mapping between category ids and the category dictionaries
tracks (Dict[int, dict]) – mapping between track ids and the track dictionaries
kpcats (Dict[int, dict]) – mapping between keypoint category ids and keypoint category dictionaries
gid_to_aids (Dict[int, List[int]]) – mapping between an image-id and annotation-ids that belong to it
cid_to_aids (Dict[int, List[int]]) – mapping between an category-id and annotation-ids that belong to it
cid_to_gids (Dict[int, List[int]]) – mapping between an category-id and image-ids that contain at least one annotation with this cateogry id.
trackid_to_aids (Dict[int, List[int]]) – mapping between a track-id and annotation-ids that belong to it
vidid_to_gids (Dict[int, List[int]]) – mapping between an video-id and images-ids that belong to it
name_to_video (Dict[str, dict]) – mapping between a video name and the video dictionary.
name_to_cat (Dict[str, dict]) – mapping between a category name and the category dictionary.
name_to_img (Dict[str, dict]) – mapping between a image name and the image dictionary.
name_to_track (Dict[str, dict]) – mapping between a track name and the track dictionary.
file_name_to_img (Dict[str, dict]) – mapping between a image file_name and the image dictionary.
- _images_set_sorted_by_frame_index(gids=None)[source]¶
Helper for ensuring that vidid_to_gids returns image ids ordered by frame index.
- _set_sorted_by_frame_index(gids=None)¶
Helper for ensuring that vidid_to_gids returns image ids ordered by frame index.
- _annots_set_sorted_by_frame_index(aids=None)[source]¶
Helper for ensuring that vidid_to_gids returns image ids ordered by frame index.
- property cid_to_gids¶
Example:
>>> import kwcoco >>> self = dset = kwcoco.CocoDataset() >>> self.index.cid_to_gids
- _add_image(gid, img)[source]¶
Example
>>> # Test adding image to video that doesnt exist >>> import kwcoco >>> self = dset = kwcoco.CocoDataset() >>> dset.add_image(file_name='frame1', video_id=1, frame_index=0) >>> dset.add_image(file_name='frame2', video_id=1, frame_index=0) >>> dset._check_integrity() >>> print('dset.index.vidid_to_gids = {!r}'.format(dset.index.vidid_to_gids)) >>> assert len(dset.index.vidid_to_gids) == 1 >>> dset.add_video(name='foo-vid', id=1) >>> assert len(dset.index.vidid_to_gids) == 1 >>> dset._check_integrity()
- _add_images(imgs)[source]¶
See ../dev/bench/bench_add_image_check.py
Note
THIS FUNCTION WAS DESIGNED FOR SPEED, AS SUCH IT DOES NOT CHECK IF THE IMAGE-IDs or FILE_NAMES ARE DUPLICATED AND WILL BLINDLY ADD DATA EVEN IF IT IS BAD. THE SINGLE IMAGE VERSION IS SLOWER BUT SAFER.
- build(parent)[source]¶
Build all id-to-obj reverse indexes from scratch.
- Parameters:
parent (kwcoco.CocoDataset) – the dataset to index
- Notation:
aid - Annotation ID gid - imaGe ID cid - Category ID vidid - Video ID tid - Track ID
Example
>>> import kwcoco >>> parent = kwcoco.CocoDataset.demo('vidshapes1', num_frames=4, rng=1) >>> index = parent.index >>> index.build(parent)
- class kwcoco.coco_dataset.MixinCocoIndex[source]¶
Bases:
objectGive the dataset top level access to index attributes
- property anns¶
- property imgs¶
- property cats¶
- property gid_to_aids¶
- property cid_to_aids¶
- property name_to_cat¶
- class kwcoco.coco_dataset.CocoDataset(data=None, tag=None, bundle_dpath=None, img_root=None, fname=None, autobuild=True)[source]¶
Bases:
AbstractCocoDataset,MixinCocoAddRemove,MixinCocoStats,MixinCocoObjects,MixinCocoDraw,MixinCocoAccessors,MixinCocoConstructors,MixinCocoExtras,MixinCocoHashing,MixinCocoIndex,MixinCocoDepricate,NiceReprThe main coco dataset class with a json dataset backend.
- Variables:
dataset (Dict) – raw json data structure. This is the base dictionary that contains {‘annotations’: List, ‘images’: List, ‘categories’: List}
index (CocoIndex) – an efficient lookup index into the coco data structure. The index defines its own attributes like
anns,cats,imgs,gid_to_aids,file_name_to_img, etc. SeeCocoIndexfor more details on which attributes are available.fpath (PathLike | None) – if known, this stores the filepath the dataset was loaded from
tag (str | None) – A tag indicating the name of the dataset.
bundle_dpath (PathLike | None) – If known, this is the root path that all image file names are relative to. This can also be manually overwritten by the user.
hashid (str | None) – If computed, this will be a hash uniquely identifing the dataset. To ensure this is computed see
kwcoco.coco_dataset.MixinCocoExtras._build_hashid().
References
http://cocodataset.org/#format http://cocodataset.org/#download
CommandLine
python -m kwcoco.coco_dataset CocoDataset --show
Example
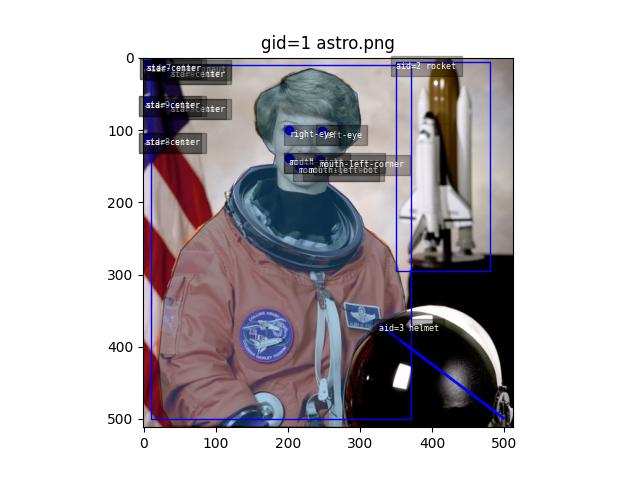
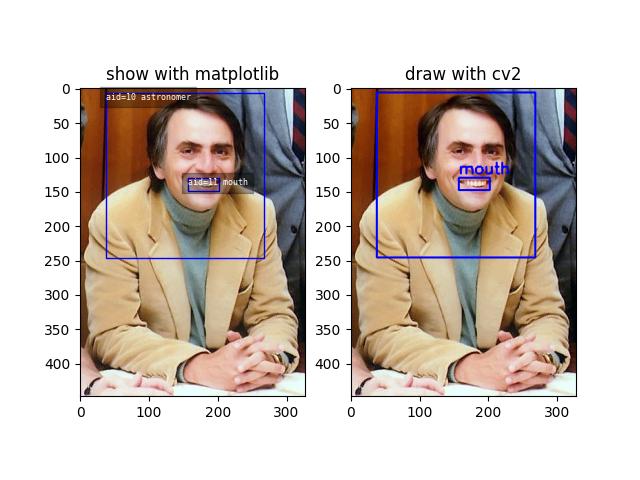
>>> from kwcoco.coco_dataset import demo_coco_data >>> import kwcoco >>> import ubelt as ub >>> # Returns a coco json structure >>> dataset = demo_coco_data() >>> # Pass the coco json structure to the API >>> self = kwcoco.CocoDataset(dataset, tag='demo') >>> # Now you can access the data using the index and helper methods >>> # >>> # Start by looking up an image by it's COCO id. >>> image_id = 1 >>> img = self.index.imgs[image_id] >>> print(ub.urepr(img, nl=1, sort=1)) { 'file_name': 'astro.png', 'id': 1, 'url': 'https://i.imgur.com/KXhKM72.png', } >>> # >>> # Use the (gid_to_aids) index to lookup annotations in the iamge >>> annotation_id = sorted(self.index.gid_to_aids[image_id])[0] >>> ann = self.index.anns[annotation_id] >>> print(ub.urepr((ub.udict(ann) - {'segmentation'}).sorted_keys(), nl=1)) { 'bbox': [10, 10, 360, 490], 'category_id': 1, 'id': 1, 'image_id': 1, 'keypoints': [247, 101, 2, 202, 100, 2], } >>> # >>> # Use annotation category id to look up that information >>> category_id = ann['category_id'] >>> cat = self.index.cats[category_id] >>> print('cat = {}'.format(ub.urepr(cat, nl=1, sort=1))) cat = { 'id': 1, 'name': 'astronaut', 'supercategory': 'human', } >>> # >>> # Now play with some helper functions, like extended statistics >>> extended_stats = self.extended_stats() >>> # xdoctest: +IGNORE_WANT >>> print('extended_stats = {}'.format(ub.urepr(extended_stats, nl=1, precision=2, sort=1))) extended_stats = { 'annots_per_img': {'mean': 3.67, 'std': 3.86, 'min': 0.00, 'max': 9.00, 'nMin': 1, 'nMax': 1, 'shape': (3,)}, 'imgs_per_cat': {'mean': 0.88, 'std': 0.60, 'min': 0.00, 'max': 2.00, 'nMin': 2, 'nMax': 1, 'shape': (8,)}, 'cats_per_img': {'mean': 2.33, 'std': 2.05, 'min': 0.00, 'max': 5.00, 'nMin': 1, 'nMax': 1, 'shape': (3,)}, 'annots_per_cat': {'mean': 1.38, 'std': 1.49, 'min': 0.00, 'max': 5.00, 'nMin': 2, 'nMax': 1, 'shape': (8,)}, 'imgs_per_video': {'empty_list': True}, } >>> # You can "draw" a raster of the annotated image with cv2 >>> canvas = self.draw_image(2) >>> # Or if you have matplotlib you can "show" the image with mpl objects >>> # xdoctest: +REQUIRES(--show) >>> from matplotlib import pyplot as plt >>> fig = plt.figure() >>> ax1 = fig.add_subplot(1, 2, 1) >>> self.show_image(gid=2) >>> ax2 = fig.add_subplot(1, 2, 2) >>> ax2.imshow(canvas) >>> ax1.set_title('show with matplotlib') >>> ax2.set_title('draw with cv2') >>> plt.show()
- Parameters:
data (str | PathLike | dict | None) – Either a filepath to a coco json file, or a dictionary containing the actual coco json structure. For a more generally coercable constructor see func:CocoDataset.coerce.
tag (str | None) – Name of the dataset for display purposes, and does not influence behavior of the underlying data structure, although it may be used via convinience methods. We attempt to autopopulate this via information in
dataif available. If unspecfied anddatais a filepath this becomes the basename.bundle_dpath (str | None) – the root of the dataset that images / external data will be assumed to be relative to. If unspecfied, we attempt to determine it using information in
data. Ifdatais a filepath, we use the dirname of that path. Ifdatais a dictionary, we look for the “img_root” key. If unspecfied and we fail to introspect then, we fallback to the current working directory.img_root (str | None) – deprecated alias for bundle_dpath
- property fpath¶
In the future we will deprecate img_root for bundle_dpath
- classmethod from_data(data, bundle_dpath=None, img_root=None)[source]¶
Constructor from a json dictionary
- Return type:
- classmethod from_image_paths(gpaths, bundle_dpath=None, img_root=None)[source]¶
Constructor from a list of images paths.
This is a convinience method.
- Parameters:
gpaths (List[str]) – list of image paths
- Return type:
Example
>>> import kwcoco >>> coco_dset = kwcoco.CocoDataset.from_image_paths(['a.png', 'b.png']) >>> assert coco_dset.n_images == 2
- classmethod from_class_image_paths(root)[source]¶
Ingest classification data in the common format where images of different categories are stored in folders with the category label.
- Parameters:
root (str | PathLike) – the path to a directory containing class-subdirectories
- Return type:
- classmethod coerce_multiple(datas, workers=0, mode='process', verbose=1, postprocess=None, ordered=True, **kwargs)[source]¶
Coerce multiple CocoDataset objects in parallel.
- Parameters:
datas (List) – list of kwcoco coercables to load
workers (int | str) – number of worker threads / processes. Can also accept coerceable workers.
mode (str) – thread, process, or serial. Defaults to process.
verbose (int) – verbosity level
postprocess (Callable | None) – A function taking one arg (the loaded dataset) to run on the loaded kwcoco dataset in background workers. This can be more efficient when postprocessing is independent per kwcoco file.
ordered (bool) – if True yields datasets in the same order as given. Otherwise results are yielded as they become available. Defaults to True.
**kwargs – arguments passed to the constructor
- Yields:
CocoDataset
- SeeAlso:
load_multiple - like this function but is a strict file-path-only loader
CommandLine
xdoctest -m kwcoco.coco_dataset CocoDataset.coerce_multiple
Example
>>> import kwcoco >>> dset1 = kwcoco.CocoDataset.demo('shapes1') >>> dset2 = kwcoco.CocoDataset.demo('shapes2') >>> dset3 = kwcoco.CocoDataset.demo('vidshapes8') >>> dsets = [dset1, dset2, dset3] >>> input_fpaths = [d.fpath for d in dsets] >>> results = list(kwcoco.CocoDataset.coerce_multiple(input_fpaths, ordered=True)) >>> result_fpaths = [r.fpath for r in results] >>> assert result_fpaths == input_fpaths >>> # Test unordered >>> results1 = list(kwcoco.CocoDataset.coerce_multiple(input_fpaths, ordered=False)) >>> result_fpaths = [r.fpath for r in results] >>> assert set(result_fpaths) == set(input_fpaths) >>> # >>> # Coerce from existing datasets >>> results2 = list(kwcoco.CocoDataset.coerce_multiple(dsets, ordered=True, workers=0)) >>> assert results2[0] is dsets[0]
- classmethod load_multiple(fpaths, workers=0, mode='process', verbose=1, postprocess=None, ordered=True, **kwargs)[source]¶
Load multiple CocoDataset objects in parallel.
- Parameters:
fpaths (List[str | PathLike]) – list of paths to multiple coco files to be loaded
workers (int) – number of worker threads / processes
mode (str) – thread, process, or serial. Defaults to process.
verbose (int) – verbosity level
postprocess (Callable | None) – A function taking one arg (the loaded dataset) to run on the loaded kwcoco dataset in background workers and returns the modified dataset. This can be more efficient when postprocessing is independent per kwcoco file.
ordered (bool) – if True yields datasets in the same order as given. Otherwise results are yielded as they become available. Defaults to True.
**kwargs – arguments passed to the constructor
- Yields:
CocoDataset
- SeeAlso:
- coerce_multiple - like this function but accepts general
coercable inputs.
- classmethod _load_multiple(_loader, inputs, workers=0, mode='process', verbose=1, postprocess=None, ordered=True, **kwargs)[source]¶
Shared logic for multiprocessing loaders.
- SeeAlso:
coerce_multiple
load_multiple
- classmethod from_coco_paths(fpaths, max_workers=0, verbose=1, mode='thread', union='try')[source]¶
Constructor from multiple coco file paths.
Loads multiple coco datasets and unions the result
Note
if the union operation fails, the list of individually loaded files is returned instead.
- Parameters:
fpaths (List[str]) – list of paths to multiple coco files to be loaded and unioned.
max_workers (int) – number of worker threads / processes
verbose (int) – verbosity level
mode (str) – thread, process, or serial
union (str | bool) – If True, unions the result datasets after loading. If False, just returns the result list. If ‘try’, then try to preform the union, but return the result list if it fails. Default=’try’
Note
This may be deprecated. Use load_multiple or coerce_multiple and then manually perform the union.
- copy()[source]¶
Deep copies this object
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> new = self.copy() >>> assert new.imgs[1] is new.dataset['images'][0] >>> assert new.imgs[1] == self.dataset['images'][0] >>> assert new.imgs[1] is not self.dataset['images'][0]
- dumps(indent=None, newlines=False)[source]¶
Writes the dataset out to the json format
- Parameters:
newlines (bool) – if True, each annotation, image, category gets its own line
indent (int | str | None) – indentation for the json file. See
json.dump()for details.newlines (bool) – if True, each annotation, image, category gets its own line.
Note
- Using newlines=True is similar to:
print(ub.urepr(dset.dataset, nl=2, trailsep=False)) However, the above may not output valid json if it contains ndarrays.
Example
>>> import kwcoco >>> import json >>> self = kwcoco.CocoDataset.demo() >>> text = self.dumps(newlines=True) >>> print(text) >>> self2 = kwcoco.CocoDataset(json.loads(text), tag='demo2') >>> assert self2.dataset == self.dataset >>> assert self2.dataset is not self.dataset
>>> text = self.dumps(newlines=True) >>> print(text) >>> self2 = kwcoco.CocoDataset(json.loads(text), tag='demo2') >>> assert self2.dataset == self.dataset >>> assert self2.dataset is not self.dataset
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.coerce('vidshapes1-msi-multisensor', verbose=3) >>> self.remove_annotations(self.annots()) >>> text = self.dumps(newlines=0, indent=' ') >>> print(text) >>> text = self.dumps(newlines=True, indent=' ') >>> print(text)
- _compress_dump_to_fileptr(file, arcname=None, indent=None, newlines=False)[source]¶
Experimental method to save compressed kwcoco files, may be folded into dump in the future.
- _dump(file, indent, newlines, compress)[source]¶
Case where we are dumping to an open file pointer. We assume this means the dataset has been written to disk.
- dump(file=None, indent=None, newlines=False, temp_file='auto', compress='auto')[source]¶
Writes the dataset out to the json format
- Parameters:
file (PathLike | IO | None) – Where to write the data. Can either be a path to a file or an open file pointer / stream. If unspecified, it will be written to the current
fpathproperty.indent (int | str | None) – indentation for the json file. See
json.dump()for details.newlines (bool) – if True, each annotation, image, category gets its own line.
temp_file (bool | str) – Argument to
safer.open(). Ignored iffileis not a PathLike object. Defaults to ‘auto’, which is False on Windows and True everywhere else.compress (bool | str) – if True, dumps the kwcoco file as a compressed zipfile. In this case a literal IO file object must be opened in binary write mode. If auto, then it will default to False unless it can introspect the file name and the name ends with .zip
Example
>>> import kwcoco >>> import ubelt as ub >>> dpath = ub.Path.appdir('kwcoco/demo/dump').ensuredir() >>> dset = kwcoco.CocoDataset.demo() >>> dset.fpath = dpath / 'my_coco_file.json' >>> # Calling dump writes to the current fpath attribute. >>> dset.dump() >>> assert dset.dataset == kwcoco.CocoDataset(dset.fpath).dataset >>> assert dset.dumps() == dset.fpath.read_text() >>> # >>> # Using compress=True can save a lot of space and it >>> # is transparent when reading files via CocoDataset >>> dset.dump(compress=True) >>> assert dset.dataset == kwcoco.CocoDataset(dset.fpath).dataset >>> assert dset.dumps() != dset.fpath.read_text(errors='replace')
Example
>>> import kwcoco >>> import ubelt as ub >>> # Compression auto-defaults based on the file name. >>> dpath = ub.Path.appdir('kwcoco/demo/dump').ensuredir() >>> dset = kwcoco.CocoDataset.demo() >>> fpath1 = dset.fpath = dpath / 'my_coco_file.zip' >>> dset.dump() >>> fpath2 = dset.fpath = dpath / 'my_coco_file.json' >>> dset.dump() >>> assert fpath1.read_bytes()[0:8] != fpath2.read_bytes()[0:8]
- _check_json_serializable(verbose=1)[source]¶
Debug which part of a coco dataset might not be json serializable
- _check_index()[source]¶
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> self._check_index() >>> # Force a failure >>> self.index.anns.pop(1) >>> self.index.anns.pop(2) >>> import pytest >>> with pytest.raises(AssertionError): >>> self._check_index()
- _abc_impl = <_abc._abc_data object>¶
- _check_pointers(verbose=1)[source]¶
Check that all category and image ids referenced by annotations exist
- union(*, disjoint_tracks=True, remember_parent=False, **kwargs)[source]¶
Merges multiple
CocoDatasetitems into one. Names and associations are retained, but ids may be different.- Parameters:
*others – a series of CocoDatasets that we will merge. Note, if called as an instance method, the “self” instance will be the first item in the “others” list. But if called like a classmethod, “others” will be empty by default.
disjoint_tracks (bool) – if True, we will assume track-names are disjoint and if two datasets share the same track-name, we will disambiguate them. Otherwise they will be copied over as-is. Defaults to True. In most cases you do not want to set this to False.
remember_parent (bool) – if True, videos and images will save information about their parent in the “union_parent” field.
**kwargs – constructor options for the new merged CocoDataset
- Returns:
a new merged coco dataset
- Return type:
CommandLine
xdoctest -m kwcoco.coco_dataset CocoDataset.union
Example
>>> import kwcoco >>> # Test union works with different keypoint categories >>> dset1 = kwcoco.CocoDataset.demo('shapes1') >>> dset2 = kwcoco.CocoDataset.demo('shapes2') >>> dset1.remove_keypoint_categories(['bot_tip', 'mid_tip', 'right_eye']) >>> dset2.remove_keypoint_categories(['top_tip', 'left_eye']) >>> dset_12a = kwcoco.CocoDataset.union(dset1, dset2) >>> dset_12b = dset1.union(dset2) >>> dset_21 = dset2.union(dset1) >>> def add_hist(h1, h2): >>> return {k: h1.get(k, 0) + h2.get(k, 0) for k in set(h1) | set(h2)} >>> kpfreq1 = dset1.keypoint_annotation_frequency() >>> kpfreq2 = dset2.keypoint_annotation_frequency() >>> kpfreq_want = add_hist(kpfreq1, kpfreq2) >>> kpfreq_got1 = dset_12a.keypoint_annotation_frequency() >>> kpfreq_got2 = dset_12b.keypoint_annotation_frequency() >>> assert kpfreq_want == kpfreq_got1 >>> assert kpfreq_want == kpfreq_got2
>>> # Test disjoint gid datasets >>> dset1 = kwcoco.CocoDataset.demo('shapes3') >>> for new_gid, img in enumerate(dset1.dataset['images'], start=10): >>> for aid in dset1.gid_to_aids[img['id']]: >>> dset1.anns[aid]['image_id'] = new_gid >>> img['id'] = new_gid >>> dset1.index.clear() >>> dset1._build_index() >>> # ------ >>> dset2 = kwcoco.CocoDataset.demo('shapes2') >>> for new_gid, img in enumerate(dset2.dataset['images'], start=100): >>> for aid in dset2.gid_to_aids[img['id']]: >>> dset2.anns[aid]['image_id'] = new_gid >>> img['id'] = new_gid >>> dset1.index.clear() >>> dset2._build_index() >>> others = [dset1, dset2] >>> merged = kwcoco.CocoDataset.union(*others) >>> print('merged = {!r}'.format(merged)) >>> print('merged.imgs = {}'.format(ub.urepr(merged.imgs, nl=1))) >>> assert set(merged.imgs) & set([10, 11, 12, 100, 101]) == set(merged.imgs)
>>> # Test data is not preserved >>> dset2 = kwcoco.CocoDataset.demo('shapes2') >>> dset1 = kwcoco.CocoDataset.demo('shapes3') >>> others = (dset1, dset2) >>> cls = self = kwcoco.CocoDataset >>> merged = cls.union(*others) >>> print('merged = {!r}'.format(merged)) >>> print('merged.imgs = {}'.format(ub.urepr(merged.imgs, nl=1))) >>> assert set(merged.imgs) & set([1, 2, 3, 4, 5]) == set(merged.imgs)
>>> # Test track-ids are mapped correctly >>> dset1 = kwcoco.CocoDataset.demo('vidshapes1') >>> dset2 = kwcoco.CocoDataset.demo('vidshapes2') >>> dset3 = kwcoco.CocoDataset.demo('vidshapes3') >>> others = (dset1, dset2, dset3) >>> for dset in others: >>> [a.pop('segmentation', None) for a in dset.index.anns.values()] >>> [a.pop('keypoints', None) for a in dset.index.anns.values()] >>> cls = self = kwcoco.CocoDataset >>> merged = cls.union(*others, disjoint_tracks=1) >>> print('dset1.anns = {}'.format(ub.urepr(dset1.anns, nl=1))) >>> print('dset2.anns = {}'.format(ub.urepr(dset2.anns, nl=1))) >>> print('dset3.anns = {}'.format(ub.urepr(dset3.anns, nl=1))) >>> print('merged.anns = {}'.format(ub.urepr(merged.anns, nl=1)))
Example
>>> import kwcoco >>> # Test empty union >>> empty_union = kwcoco.CocoDataset.union() >>> assert len(empty_union.index.imgs) == 0
Todo
[ ] are supercategories broken?
[ ] reuse image ids where possible
[ ] reuse annotation / category ids where possible
[X] handle case where no inputs are given
[x] disambiguate track-ids
[x] disambiguate video-ids
- subset(gids, copy=False, autobuild=True)[source]¶
Return a subset of the larger coco dataset by specifying which images to port. All annotations in those images will be taken.
- Parameters:
gids (List[int]) – image-ids to copy into a new dataset
copy (bool) – if True, makes a deep copy of all nested attributes, otherwise makes a shallow copy. Defaults to True.
autobuild (bool) – if True will automatically build the fast lookup index. Defaults to True.
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> gids = [1, 3] >>> sub_dset = self.subset(gids) >>> assert len(self.index.gid_to_aids) == 3 >>> assert len(sub_dset.gid_to_aids) == 2
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo('vidshapes2') >>> gids = [1, 2] >>> sub_dset = self.subset(gids, copy=True) >>> assert len(sub_dset.index.videos) == 1 >>> assert len(self.index.videos) == 2
Example
>>> import kwcoco >>> self = kwcoco.CocoDataset.demo() >>> sub1 = self.subset([1]) >>> sub2 = self.subset([2]) >>> sub3 = self.subset([3]) >>> others = [sub1, sub2, sub3] >>> rejoined = kwcoco.CocoDataset.union(*others) >>> assert len(sub1.anns) == 9 >>> assert len(sub2.anns) == 2 >>> assert len(sub3.anns) == 0 >>> assert rejoined.basic_stats() == self.basic_stats()
- view_sql(force_rewrite=False, memory=False, backend='sqlite', sql_db_fpath=None)[source]¶
Create a cached SQL interface to this dataset suitable for large scale multiprocessing use cases.
- Parameters:
force_rewrite (bool) – if True, forces an update to any existing cache file on disk
memory (bool) – if True, the database is constructed in memory.
backend (str) – sqlite or postgresql
sql_db_fpath (str | PathLike | None) – overrides the database uri
Note
This view cache is experimental and currently depends on the timestamp of the file pointed to by
self.fpath. In other words dont use this on in-memory datasets.CommandLine
KWCOCO_WITH_POSTGRESQL=1 xdoctest -m /home/joncrall/code/kwcoco/kwcoco/coco_dataset.py CocoDataset.view_sql
Example
>>> # xdoctest: +REQUIRES(module:sqlalchemy) >>> # xdoctest: +REQUIRES(env:KWCOCO_WITH_POSTGRESQL) >>> # xdoctest: +REQUIRES(module:psycopg2) >>> import kwcoco >>> dset = kwcoco.CocoDataset.demo('vidshapes32') >>> postgres_dset = dset.view_sql(backend='postgresql', force_rewrite=True) >>> sqlite_dset = dset.view_sql(backend='sqlite', force_rewrite=True) >>> list(dset.anns.keys()) >>> list(postgres_dset.anns.keys()) >>> list(sqlite_dset.anns.keys())
- kwcoco.coco_dataset.demo_coco_data()[source]¶
Simple data for testing.
This contains several non-standard fields, which help ensure robustness of functions tested with this data. For more compliant demodata see the
kwcoco.demodatasubmodule.Example
>>> # xdoctest: +REQUIRES(--show) >>> import kwcoco >>> from kwcoco.coco_dataset import demo_coco_data >>> dataset = demo_coco_data() >>> self = kwcoco.CocoDataset(dataset, tag='demo') >>> import kwplot >>> kwplot.autompl() >>> self.show_image(gid=1) >>> kwplot.show_if_requested()