kwcoco.metrics.confusion_measures module¶
Classes that store accumulated confusion measures (usually derived from confusion vectors).
- For each chosen threshold value:
thresholds[i] - the i-th threshold value
The primary data we manipulate are arrays of “confusion” counts, i.e.
tp_count[i] - true positives at the i-th threshold
fp_count[i] - false positives at the i-th threshold
fn_count[i] - false negatives at the i-th threshold
tn_count[i] - true negatives at the i-th threshold
- class kwcoco.metrics.confusion_measures.Measures(info)[source]¶
-
Holds accumulated confusion counts, and derived measures
Example
>>> from kwcoco.metrics.confusion_vectors import BinaryConfusionVectors # NOQA >>> binvecs = BinaryConfusionVectors.demo(n=100, p_error=0.5) >>> self = binvecs.measures() >>> print('self = {!r}'.format(self)) >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> self.draw(doclf=True) >>> self.draw(key='pr', pnum=(1, 2, 1)) >>> self.draw(key='roc', pnum=(1, 2, 2)) >>> kwplot.show_if_requested()
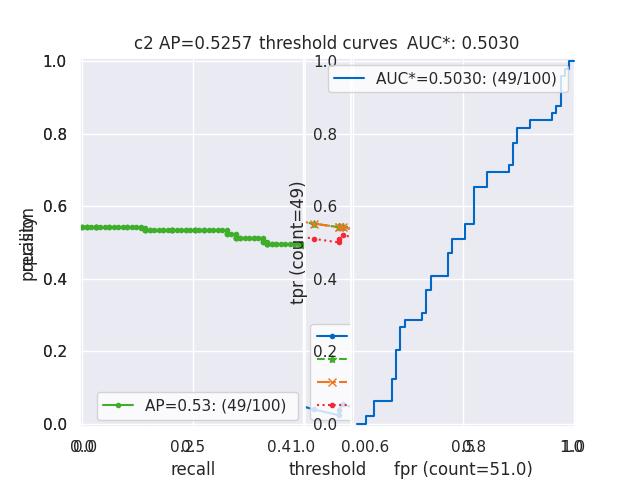
- property catname¶
- draw(key=None, prefix='', **kw)[source]¶
Example
>>> # xdoctest: +REQUIRES(module:kwplot) >>> # xdoctest: +REQUIRES(module:pandas) >>> from kwcoco.metrics.confusion_vectors import ConfusionVectors # NOQA >>> cfsn_vecs = ConfusionVectors.demo() >>> ovr_cfsn = cfsn_vecs.binarize_ovr(keyby='name') >>> self = ovr_cfsn.measures()['perclass'] >>> self.draw('mcc', doclf=True, fnum=1) >>> self.draw('pr', doclf=1, fnum=2) >>> self.draw('roc', doclf=1, fnum=3)
- summary_plot(fnum=1, title='', subplots='auto')[source]¶
Example
>>> from kwcoco.metrics.confusion_measures import * # NOQA >>> from kwcoco.metrics.confusion_vectors import ConfusionVectors # NOQA >>> cfsn_vecs = ConfusionVectors.demo(n=3, p_error=0.5) >>> binvecs = cfsn_vecs.binarize_classless() >>> self = binvecs.measures() >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> self.summary_plot() >>> kwplot.show_if_requested()
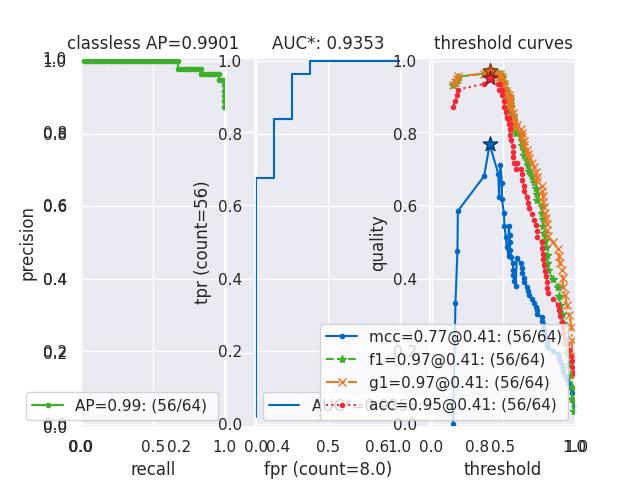
- classmethod demo(**kwargs)[source]¶
Create a demo Measures object for testing / demos
- Parameters:
**kwargs – passed to
BinaryConfusionVectors.demo(). some valid keys are: n, rng, p_rue, p_error, p_miss.
- classmethod combine(tocombine, precision=None, growth=None, thresh_bins=None)[source]¶
Combine binary confusion metrics
- Parameters:
tocombine (List[Measures]) – a list of measures to combine into one
precision (int | None) – If specified rounds thresholds to this precision which can prevent a RAM explosion when combining a large number of measures. However, this is a lossy operation and will impact the underlying scores. NOTE: use
growthinstead.growth (int | None) – if specified this limits how much the resulting measures are allowed to grow by. If None, growth is unlimited. Otherwise, if growth is ‘max’, the growth is limited to the maximum length of an input. We might make this more numerical in the future.
thresh_bins (int | None) – Force this many threshold bins.
- Returns:
kwcoco.metrics.confusion_measures.Measures
Example
>>> from kwcoco.metrics.confusion_measures import * # NOQA >>> measures1 = Measures.demo(n=15) >>> measures2 = measures1 >>> tocombine = [measures1, measures2] >>> new_measures = Measures.combine(tocombine) >>> new_measures.reconstruct() >>> print('new_measures = {!r}'.format(new_measures)) >>> print('measures1 = {!r}'.format(measures1)) >>> print('measures2 = {!r}'.format(measures2)) >>> print(ub.urepr(measures1.__json__(), nl=1, sort=0)) >>> print(ub.urepr(measures2.__json__(), nl=1, sort=0)) >>> print(ub.urepr(new_measures.__json__(), nl=1, sort=0)) >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> kwplot.figure(fnum=1) >>> new_measures.summary_plot() >>> measures1.summary_plot() >>> measures1.draw('roc') >>> measures2.draw('roc') >>> new_measures.draw('roc')
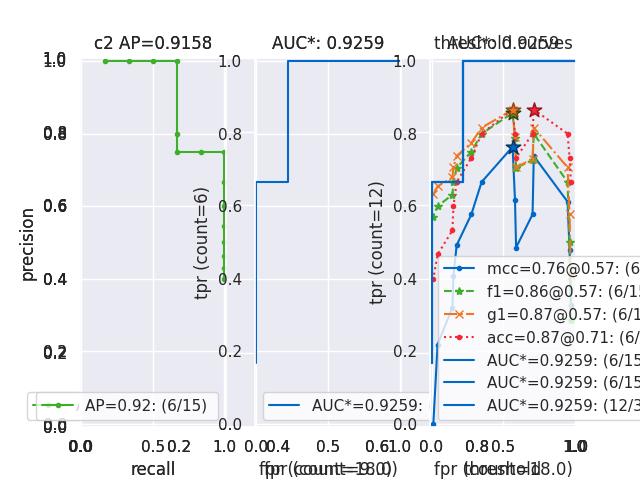
Example
>>> # Demonstrate issues that can arrise from choosing a precision >>> # that is too low when combining metrics. Breakpoints >>> # between different metrics can get muddled, but choosing a >>> # precision that is too high can overwhelm memory. >>> from kwcoco.metrics.confusion_measures import * # NOQA >>> base = ub.map_vals(np.asarray, { >>> 'tp_count': [ 1, 1, 2, 2, 2, 2, 3], >>> 'fp_count': [ 0, 1, 1, 2, 3, 4, 5], >>> 'fn_count': [ 1, 1, 0, 0, 0, 0, 0], >>> 'tn_count': [ 5, 4, 4, 3, 2, 1, 0], >>> 'thresholds': [.0, .0, .0, .0, .0, .0, .0], >>> }) >>> # Make tiny offsets to thresholds >>> rng = kwarray.ensure_rng(0) >>> n = len(base['thresholds']) >>> offsets = [ >>> sorted(rng.rand(n) * 10 ** -rng.randint(4, 7))[::-1] >>> for _ in range(20) >>> ] >>> tocombine = [] >>> for offset in offsets: >>> base_n = base.copy() >>> base_n['thresholds'] += offset >>> measures_n = Measures(base_n).reconstruct() >>> tocombine.append(measures_n) >>> for precision in [6, 5, 2]: >>> combo = Measures.combine(tocombine, precision=precision).reconstruct() >>> print('precision = {!r}'.format(precision)) >>> print('combo = {}'.format(ub.urepr(combo, nl=1))) >>> print('num_thresholds = {}'.format(len(combo['thresholds']))) >>> for growth in [None, 'max', 'log', 'root', 'half']: >>> combo = Measures.combine(tocombine, growth=growth).reconstruct() >>> print('growth = {!r}'.format(growth)) >>> print('combo = {}'.format(ub.urepr(combo, nl=1))) >>> print('num_thresholds = {}'.format(len(combo['thresholds']))) >>> #print(combo.counts().pandas())
Example
>>> # Test case: combining a single measures should leave it unchanged >>> from kwcoco.metrics.confusion_measures import * # NOQA >>> measures = Measures.demo(n=40, p_true=0.2, p_error=0.4, p_miss=0.6) >>> df1 = measures.counts().pandas().fillna(0) >>> print(df1) >>> tocombine = [measures] >>> combo = Measures.combine(tocombine) >>> df2 = combo.counts().pandas().fillna(0) >>> print(df2) >>> assert np.allclose(df1, df2)
>>> combo = Measures.combine(tocombine, thresh_bins=2) >>> df3 = combo.counts().pandas().fillna(0) >>> print(df3)
>>> # I am NOT sure if this is correct or not >>> thresh_bins = 20 >>> combo = Measures.combine(tocombine, thresh_bins=thresh_bins) >>> df4 = combo.counts().pandas().fillna(0) >>> print(df4)
>>> combo = Measures.combine(tocombine, thresh_bins=np.linspace(0, 1, 20)) >>> df4 = combo.counts().pandas().fillna(0) >>> print(df4)
assert np.allclose(combo[‘thresholds’], measures[‘thresholds’]) assert np.allclose(combo[‘fp_count’], measures[‘fp_count’]) assert np.allclose(combo[‘tp_count’], measures[‘tp_count’]) assert np.allclose(combo[‘tp_count’], measures[‘tp_count’])
globals().update(xdev.get_func_kwargs(Measures.combine))
Example
>>> # Test degenerate case >>> from kwcoco.metrics.confusion_measures import * # NOQA >>> tocombine = [ >>> {'fn_count': [0.0], 'fp_count': [359980.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [7747.0]}, >>> {'fn_count': [0.0], 'fp_count': [360849.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [424.0]}, >>> {'fn_count': [0.0], 'fp_count': [367003.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [991.0]}, >>> {'fn_count': [0.0], 'fp_count': [367976.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [1017.0]}, >>> {'fn_count': [0.0], 'fp_count': [676338.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [7067.0]}, >>> {'fn_count': [0.0], 'fp_count': [676348.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [7406.0]}, >>> {'fn_count': [0.0], 'fp_count': [676626.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [7858.0]}, >>> {'fn_count': [0.0], 'fp_count': [676693.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [10969.0]}, >>> {'fn_count': [0.0], 'fp_count': [677269.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [11188.0]}, >>> {'fn_count': [0.0], 'fp_count': [677331.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [11734.0]}, >>> {'fn_count': [0.0], 'fp_count': [677395.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [11556.0]}, >>> {'fn_count': [0.0], 'fp_count': [677418.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [11621.0]}, >>> {'fn_count': [0.0], 'fp_count': [677422.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [11424.0]}, >>> {'fn_count': [0.0], 'fp_count': [677648.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [9804.0]}, >>> {'fn_count': [0.0], 'fp_count': [677826.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [2470.0]}, >>> {'fn_count': [0.0], 'fp_count': [677834.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [2470.0]}, >>> {'fn_count': [0.0], 'fp_count': [677835.0], 'thresholds': [0.0], 'tn_count': [0.0], 'tp_count': [2470.0]}, >>> {'fn_count': [11123.0, 0.0], 'fp_count': [0.0, 676754.0], 'thresholds': [0.0002442002442002442, 0.0], 'tn_count': [676754.0, 0.0], 'tp_count': [2.0, 11125.0]}, >>> {'fn_count': [7738.0, 0.0], 'fp_count': [0.0, 676466.0], 'thresholds': [0.0002442002442002442, 0.0], 'tn_count': [676466.0, 0.0], 'tp_count': [0.0, 7738.0]}, >>> {'fn_count': [8653.0, 0.0], 'fp_count': [0.0, 676341.0], 'thresholds': [0.0002442002442002442, 0.0], 'tn_count': [676341.0, 0.0], 'tp_count': [0.0, 8653.0]}, >>> ] >>> thresh_bins = np.linspace(0, 1, 4) >>> combo = Measures.combine(tocombine, thresh_bins=thresh_bins).reconstruct() >>> print('tocombine = {}'.format(ub.urepr(tocombine, nl=2))) >>> print('thresh_bins = {!r}'.format(thresh_bins)) >>> print(ub.urepr(combo.__json__(), nl=1)) >>> for thresh_bins in [4096, 1]: >>> combo = Measures.combine(tocombine, thresh_bins=thresh_bins).reconstruct() >>> print('thresh_bins = {!r}'.format(thresh_bins)) >>> print('combo = {}'.format(ub.urepr(combo, nl=1))) >>> print('num_thresholds = {}'.format(len(combo['thresholds']))) >>> for precision in [6, 5, 2]: >>> combo = Measures.combine(tocombine, precision=precision).reconstruct() >>> print('precision = {!r}'.format(precision)) >>> print('combo = {}'.format(ub.urepr(combo, nl=1))) >>> print('num_thresholds = {}'.format(len(combo['thresholds']))) >>> for growth in [None, 'max', 'log', 'root', 'half']: >>> combo = Measures.combine(tocombine, growth=growth).reconstruct() >>> print('growth = {!r}'.format(growth)) >>> print('combo = {}'.format(ub.urepr(combo, nl=1))) >>> print('num_thresholds = {}'.format(len(combo['thresholds'])))
- kwcoco.metrics.confusion_measures._combine_threshold(tocombine_thresh, thresh_bins, growth, precision)[source]¶
Logic to take care of combining thresholds in the case bins are not given
This can be fairly slow and lead to unnecessary memory usage
- kwcoco.metrics.confusion_measures.reversable_diff(arr, assume_sorted=1, reverse=False)[source]¶
Does a reversable array difference operation.
This will be used to find positions where accumulation happened in confusion count array.
- class kwcoco.metrics.confusion_measures.PerClass_Measures(cx_to_info)[source]¶
-
- draw(key='mcc', prefix='', **kw)[source]¶
Example
>>> # xdoctest: +REQUIRES(module:kwplot) >>> from kwcoco.metrics.confusion_vectors import ConfusionVectors # NOQA >>> cfsn_vecs = ConfusionVectors.demo() >>> ovr_cfsn = cfsn_vecs.binarize_ovr(keyby='name') >>> self = ovr_cfsn.measures()['perclass'] >>> self.draw('mcc', doclf=True, fnum=1) >>> self.draw('pr', doclf=1, fnum=2) >>> self.draw('roc', doclf=1, fnum=3)
- summary_plot(fnum=1, title='', subplots='auto')[source]¶
CommandLine
python ~/code/kwcoco/kwcoco/metrics/confusion_measures.py PerClass_Measures.summary_plot --show
Example
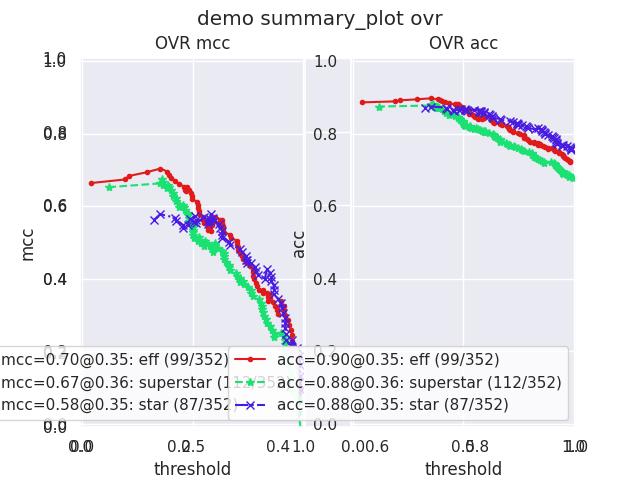
>>> from kwcoco.metrics.confusion_measures import * # NOQA >>> from kwcoco.metrics.detect_metrics import DetectionMetrics >>> dmet = DetectionMetrics.demo( >>> n_fp=(0, 1), n_fn=(0, 3), nimgs=32, nboxes=(0, 32), >>> classes=3, rng=0, newstyle=1, box_noise=0.7, cls_noise=0.2, score_noise=0.3, with_probs=False) >>> cfsn_vecs = dmet.confusion_vectors() >>> ovr_cfsn = cfsn_vecs.binarize_ovr(keyby='name', ignore_classes=['vector', 'raster']) >>> self = ovr_cfsn.measures()['perclass'] >>> # xdoctest: +REQUIRES(--show) >>> import kwplot >>> kwplot.autompl() >>> import seaborn as sns >>> sns.set() >>> self.summary_plot(title='demo summary_plot ovr', subplots=['pr', 'roc']) >>> kwplot.show_if_requested() >>> self.summary_plot(title='demo summary_plot ovr', subplots=['mcc', 'acc'], fnum=2)
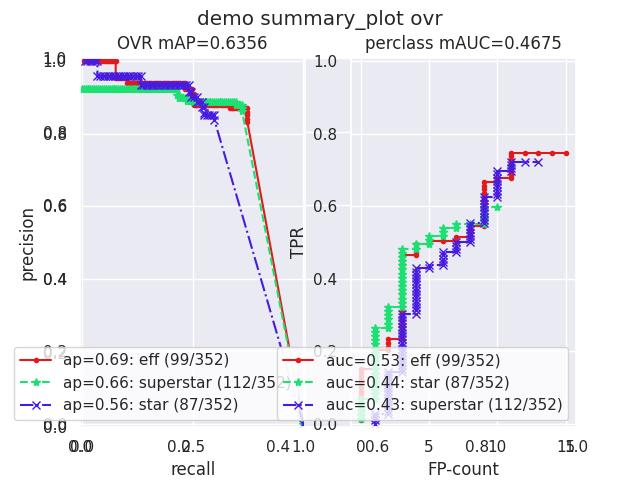
- class kwcoco.metrics.confusion_measures.MeasureCombiner(precision=None, growth=None, thresh_bins=None)[source]¶
Bases:
objectHelper to iteravely combine binary measures generated by some process
Example
>>> from kwcoco.metrics.confusion_measures import * # NOQA >>> from kwcoco.metrics.confusion_vectors import BinaryConfusionVectors >>> rng = kwarray.ensure_rng(0) >>> bin_combiner = MeasureCombiner(growth='max') >>> for _ in range(80): >>> bin_cfsn_vecs = BinaryConfusionVectors.demo(n=rng.randint(40, 50), rng=rng, p_true=0.2, p_error=0.4, p_miss=0.6) >>> bin_measures = bin_cfsn_vecs.measures() >>> bin_combiner.submit(bin_measures) >>> combined = bin_combiner.finalize() >>> print('combined = {!r}'.format(combined))
- property queue_size¶
- class kwcoco.metrics.confusion_measures.OneVersusRestMeasureCombiner(precision=None, growth=None, thresh_bins=None)[source]¶
Bases:
objectHelper to iteravely combine ovr measures generated by some process
Example
>>> from kwcoco.metrics.confusion_measures import * # NOQA >>> from kwcoco.metrics.confusion_vectors import OneVsRestConfusionVectors >>> rng = kwarray.ensure_rng(0) >>> ovr_combiner = OneVersusRestMeasureCombiner(growth='max') >>> for _ in range(80): >>> ovr_cfsn_vecs = OneVsRestConfusionVectors.demo() >>> ovr_measures = ovr_cfsn_vecs.measures() >>> ovr_combiner.submit(ovr_measures) >>> combined = ovr_combiner.finalize() >>> print('combined = {!r}'.format(combined))